파이썬 - tensorflow 2.6 NVidia GPU 사용 방법
tensorflow 모듈 설치 후,
c:\temp> pip install tensorflow
...[생략]...
Successfully installed gast-0.4.0 grpcio-1.39.0 h5py-3.1.0 tensorflow-2.6.0 tensorflow-estimator-2.6.0
다음과 같이 import만 해도,
import tensorflow as tf
이런 경고가 발생할 수 있습니다.
2021-08-22 18:34:05.288193: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2021-08-22 18:34:05.288405: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
그런 경우, 최신 CUDA Toolkit을 설치해 줍니다.
CUDA Toolkit Download
; https://developer.nvidia.com/cuda-toolkit
이후에는 다음과 같이 코딩을 해도 일단 오류가 발생하지 않습니다.
import tensorflow as tf
print(tf.__version__) # 출력 결과: 2.6.0
print(tf.version.VERSION) # 2.6.0
print(tf.version.GIT_VERSION) # v2.6.0-rc2-32-g919f693420e
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU'))) # Num GPUs Available: 1
그런데, 다음의 코드를 추가해 실행하면,
print(tf.config.list_physical_devices('GPU'))
이런 오류가 발생합니다.
2021-08-22 21:47:53.395396: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudnn64_8.dll'; dlerror: cudnn64_8.dll not found
2021-08-22 21:47:53.395617: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1835] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
링크(
https://www.tensorflow.org/install/gpu)에 보면, "Software requirements"로 다음의 항목들이 나옵니다.
- NVIDIA® GPU drivers - CUDA® 11.2 requires 450.80.02 or higher.
- CUDA® Toolkit - TensorFlow supports CUDA® 11.2 (TensorFlow >= 2.5.0)
- CUPTI ships with the CUDA® Toolkit.
- cuDNN SDK 8.1.0 cuDNN versions
- (Optional) TensorRT 6.0 to improve latency and throughput for inference on some models.
아하... "cuDNN SDK 8.1.0 cuDNN versions" 항목은 별도로 설치가 필요한 거군요. 따라서, 다음의 경로에서 최신 버전을 다운로드합니다.
cuDNN Download
; https://developer.nvidia.com/cudnn
참고로, 다운로드할 항목의 이름이 "cuDNN Library for Windows (x86)"라는 식으로 "(x64)"가 아니라 "(x86)"으로 명시돼 있는데, 그냥 인텔 아키텍처에 대한 통칭으로서 x86을 표기한 듯합니다. 따라서 그냥 받아 보면 파일명이 "cudnn-11.4-windows-x64-v8.2.2.26.zip"라고 되어 있으므로 64비트가 맞습니다.
그런데 문제는 zip 파일이라 어디다 설치해야 할지를 알 수가 없습니다. 물론 PATH 환경 변수에 걸어두면 되겠는데요, 그래도 아래의 글을 보니,
How to Install the NVIDIA CUDA Driver, CUDA Toolkit, CuDNN, and TensorRT on Windows
; https://levelup.gitconnected.com/how-to-install-the-nvidia-cuda-driver-cuda-toolkit-cudnn-and-tensorrt-on-windows-af58647b6d9a#078b
그냥 CUDA Toolkit이 설치된 디렉터리의 bin으로 복사하라고 합니다. 보니까, 실제로 .\cudnn-11.4-windows-x64-v8.2.2.26\cuda 디렉터리 하위의 bin, include, lib에 있는 파일들이 "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4" 디렉터리 하위의 내용과 겹치지 않기 때문에 충돌 걱정 없이 그대로 복사해도 됩니다.
끝이군요. ^^ 이제 다시 Python 스크립트를 실행하면 다음과 같은 결과를 확인할 수 있습니다.
import tensorflow as tf
print(tf.__version__) # 출력 결과: 2.6.0
print(tf.config.list_physical_devices('GPU')) # 출력 결과: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
혹은 더 자세한 정보를 원한다면 이렇게 해 주시고.
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
""" 출력 결과
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 16660298716077284787
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 6966018048
locality {
bus_id: 1
links {
}
}
incarnation: 12004974687831180911
physical_device_desc: "device: 0, name: NVIDIA GeForce GTX 1070, pci bus id: 0000:01:00.0, compute capability: 6.1"
]
"""
예제를 하나 가져와 볼까요? ^^
딥 러닝 입문
; https://e-koreatech.step.or.kr/page/lms/?m1=course&course_id=170363&m2=course_detail
위의 강좌에 있는 파이썬 예제 코드를,
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
import random
import numpy as np
import os
import datetime
data_cnt = 100
random.seed(0) #테스트를 위해!
x_data = []
for i in range(data_cnt):
x_data.append([random.randint(7, 20), random.randint(80, 130)])
x_data.append([random.randint(1, 10), random.randint(50, 100)])
y_data = []
for i in range(data_cnt):
y_data.append(1)
y_data.append(0)
X_train = np.array(x_data)
Y_train = np.array(y_data)
model = Sequential()
model.add(Dense(20, input_dim=2, activation='relu'))
model.add(Dense(10,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
now = datetime.datetime.now()
hist = model.fit(X_train, Y_train, epochs=200, batch_size=10, validation_data=(X_train, Y_train))
print('elapsed: ', datetime.datetime.now() - now)
# 모델 평가 및 분석
x_data = []
for i in range(10):
x_data.append([random.randint(7, 20), random.randint(80, 130)])
x_data.append([random.randint(1, 10), random.randint(50, 100)])
y_data = []
for i in range(10):
y_data.append(1)
y_data.append(0)
X_test = np.array(x_data)
Y_test = np.array(y_data)
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=1)
print('')
print('loss:', str(loss_and_metrics[0]))
print('accuracy', str(loss_and_metrics[1]))
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train_loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
acc_ax.plot(hist.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
실행해 보면, 다음과 같은 결과를 얻게 됩니다.
Num GPUs Available: 1
2021-08-29 16:59:31.204079: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-08-29 16:59:31.824942: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 6643 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1070, pci bus id: 0000:01:00.0, compute capability: 6.1
2021-08-29 16:59:32.157767: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
...[생략]...
Epoch 91/200
20/20 [==============================] - 0s 6ms/step - loss: 0.4118 - accuracy: 0.7800 - val_loss: 0.4032 - val_accuracy: 0.7600
Epoch 92/200
20/20 [==============================] - 0s 7ms/step - loss: 0.4047 - accuracy: 0.7700 - val_loss: 0.4038 - val_accuracy: 0.7550
Epoch 93/200
20/20 [==============================] - 0s 6ms/step - loss: 0.4028 - accuracy: 0.7500 - val_loss: 0.4045 - val_accuracy: 0.7700
elapsed: 0:00:26.272990 // i5-4670 CPU인 경우
이때의 CPU와 GPU 자원 소비 상황을 보면 이렇습니다.
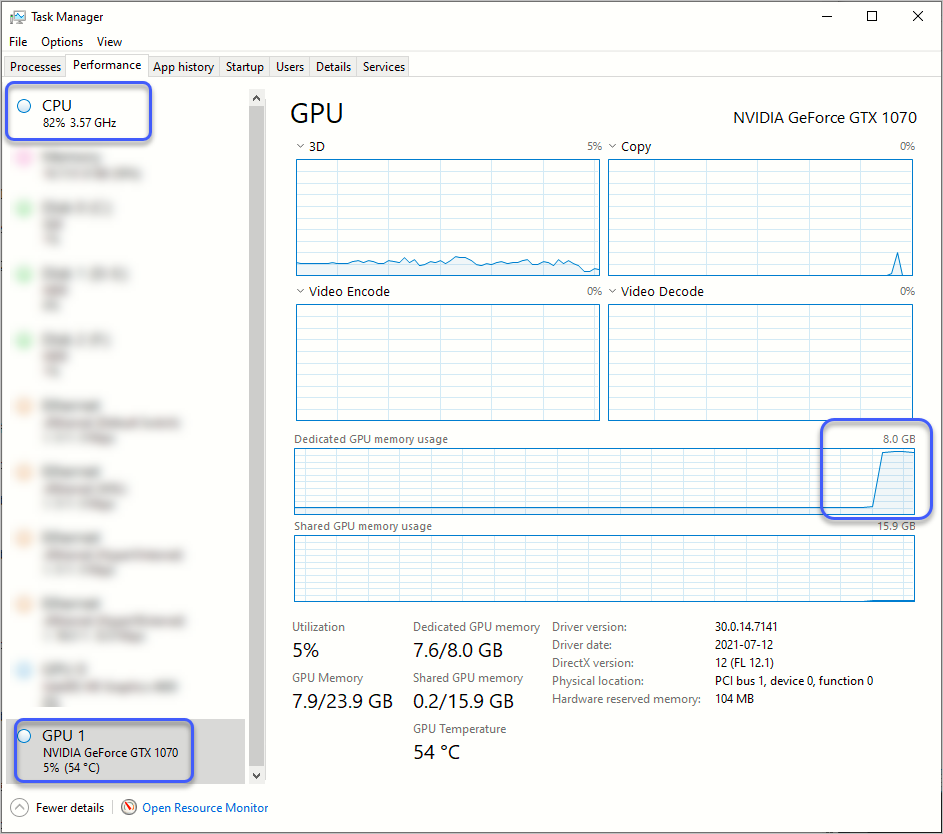
GPU의 경우 "Dedicated GPU memory usage"는 거의 최대로 올라가는 반면 GPU 자체의 "Utilization"은 높지 않습니다. 반면, 여전히 CPU 사용량은 높은데요, 사실 이게 GPU 연산이 된 것인지조차 의심스럽습니다. ^^;
게다가 출력 정보에 보면 "This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2"라는 메시지가 나오는데요, 검색해 보면 저 옵션을 넣고 재빌드를 해야 한다고 합니다. 아마도 저 옵션의 tensorflow 빌드라면 CPU 사용량이 더 낮거나, 아니면 좀 더 빠른 시간에 끝나지 않을까... 예상을 해봅니다.
참고로, "This TensorFlow binary is ..." 정보 메시지가 귀찮을 수 있는데요, 어차피 새로 빌드를 하지 않는다면 계속 봐야 하므로 그냥 옵션을 통해 꺼 두시는 것이 좋습니다. 방법은 사용 전에, 다음과 같은 환경 변수를 추가하면 됩니다.
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
재미있는 건, GPU 사용을 비활성화시키면,
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
학습 시간이 "elapsed: 0:00:09.787607"로 나와 오히려 3배 정도 빠른 성능을 보였습니다. 그러니까, 아마도 "
CUDA로 작성한 RGB2RGBA 성능" 글에 쓴 것처럼 GPU 메모리 복사 시간에 따른 오버헤드가 더 큰 것으로 보입니다. 따라서 GPU 사용에 대한 이득을 보려면 kernel 함수에 해당하는 코드가 충분한 연산 코드를 담고 있어야 하는 것입니다.
이를 테스트하기 위해 "
딥 러닝 입문" 강의에 나온 MNIST 예제를,
from datetime import datetime
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
import os
# CPU 사용으로 테스트하려면 주석 제거
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train, X_test = X_train/255.0, X_test/255.0
number_of_data = len(X_train)
train_count = 50000
val_count = 10000
X_val = X_train[number_of_data - val_count:]
Y_val = Y_train[number_of_data - val_count:]
X_train = X_train[:train_count]
Y_train = Y_train[:train_count]
# mnist dataset: width 28 x height 28
X_train = X_train.reshape(train_count, 784).astype('float32')
X_val = X_val.reshape(val_count, 784).astype('float32')
X_test = X_test.reshape(10000, 784).astype('float32')
Y_train = utils.to_categorical(Y_train, 10)
Y_val = utils.to_categorical(Y_val, 10)
Y_test = utils.to_categorical(Y_test, 10)
model = Sequential()
model.add(Dense(units=512, input_dim=28*28, activation='relu'))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=32, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
now = datetime.now()
hist = model.fit(X_train, Y_train, epochs=20, batch_size=50, validation_data=(X_val, Y_val))
print('elapsed: ', datetime.now() - now)
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
print('')
print('loss: ', str(loss_and_metrics[0]))
print('accuracy: ', str(loss_and_metrics[1]))
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
acc_ax.plot(hist.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
일부러 신경망을 512, 256, 128, 64, 32, 10으로 적층 시켜 테스트를 해보면 다음과 같은 결과를 얻게 됩니다.
GPU 사용: 0:01:36.024432
CPU 사용: 0:01:29.706344
이전에는 3배나 빨랐던 CPU 학습이 이젠 GPU와 비교해 차이가 많이 줄었습니다. 이런 점을 고려해봤을 때, 학습시 epochs 옵션을 1로 놓고 CPU와 GPU의 속도를 테스트한 다음 진행하는 것도 좋을 것입니다.
자신의 PC에 설치된 NVidia CUDA Toolokt 버전이 예전 것이고, 그 버전을 고수해야 한다면 tensorflow의 버전을 낮춰서 설치해야 합니다. 이에 대해서는 다음의 글을 참고하세요.
tensorflow 에러 해결: Could not load 'cudart64_110.dll'; dlerror:
; https://deep-deep-deep.tistory.com/71
Tensorflow 에러 해결: Could not load dynamic library
; https://deep-deep-deep.tistory.com/83
또한, 웹에 검색해 보면 tensorflow-gpu를 설치하라는 글이 나오는데,
pip install tensorflow-gpu
"
https://www.tensorflow.org/install/gpu" 링크를 보면, 그건 지난 1.15 이하 버전의 tensorflow인 경우를 대상으로 합니다.
GPU 사용 관련한 공식 문서는 아래에 있습니다.
Use a GPU
; https://www.tensorflow.org/guide/gpu
GPU가 1개 이상이라면 본문의 예제를 다음과 같이 변경해 수행해 볼 수 있을 텐데요,
# [TF 2.x] TensorFlow 2.0에서 multi GPU 사용하기 - 텐서플로우 문제 해결
# ; https://lv99.tistory.com/12
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = Sequential()
model.add(Dense(20, input_dim=2, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
제가 NVidia GPU가 하나밖에 없어서 테스트를 할 수 없었지만, 어쨌든 1개인 상태에서 저렇게 코드를 바꿔도 동작은 합니다. 단지, 뭔가 쓸데없는 코드가 수행돼서 그런지 다음과 같이 오히려 1회 학습 시간이 배나 걸리는 것을 확인할 수 있습니다.
...[생략]...
20/20 [==============================] - 0s 12ms/step - loss: 0.1951 - accuracy: 0.9250 - val_loss: 0.2019 - val_accuracy: 0.9050
Epoch 197/200
20/20 [==============================] - 0s 11ms/step - loss: 0.1870 - accuracy: 0.9350 - val_loss: 0.1855 - val_accuracy: 0.9300
Epoch 198/200
elapsed: 0:00:52.010992 // i5-4670 CPU인 경우
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]