CUDA의 인덱싱 관련 용어 - blockIdx, threadIdx, blockDim, gridDim
blockDim과 gridDim의 차이점을 이해하기에 앞서 우선 block이 뭔지에 대해 알아야 합니다.
CUDA 런타임은 N 개의 커널 복사본을 만들고 그것을 병렬로 실행할 수 있는데 여기서의 병렬로 실행되는 복사본 각각을 block이라고 합니다. 그리고 kernel 함수를 개시할 때 첫 번째 인자로 그 크기를 명시합니다.
kernel<<<2,1>>>();
즉, 위의 커널 함수 호출은 2개의 복사본(block)이 생성됩니다.
이때 복사본 각각은 자신의 Task id를 blockId.x로 구분할 수 있습니다.
__global__ void kernel()
{
int taskId = blockIdx.x; // 2개의 block이므로 [0, 1]의 범위
}
커널 함수의 첫 번째 인자로 전달하는 block의 수는 3차원까지 지정할 수 있습니다.
dim3 grid(2, 3);
kernel<<<grid, 1>>>();
위의 경우 총 블록의 수는 2 * 3 = 6입니다. 아울러 블록의 각 차원에 대한 최댓값은 cudaGetDeviceProperties로 구할 수 있습니다. (cudaDeviceProp.maxGridSize[3])
GTX 1070, GTX 960, GT 640M의 cudaGetDeviceProperties 출력 결과
; https://www.sysnet.pe.kr/2/0/11472
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
특이하게 1차원인 경우 2147483647까지 가능하지만, y, z에 해당하는 2와 3차원은 인자 값이 65535로 제한되어 있습니다. 비록 x, y, z 차원의 곱이 상상을 초월할 정도로 커지지만 최대 생성할 수 있는 블록의 수는 (테스트해보면) 1차원에 지정된 수의 값과 같습니다. (그런데.... 정말로 블록을 21억 개나 보유가 가능할까요? 아니면 부분적으로 GPU에 의해 적당하게 나눠서 관리할까요?)
즉,
kernel<<2147483648, 1>>>();
로 실행하면 cudaErrorInvalidConfiguration(9) 오류가 발생하는 반면, 범위 내에 속하는 경우,
kernel<<2147483647, 1>>>();
정상적으로 구동이 됩니다.
지정된 모든 블록은 Grid라고 불립니다. 즉 다음의 경우,
dim3 grid(2, 3);
kernel<<<grid, 1>>>();
총 6개의 블록을 갖는 grid가 운영되는 것입니다. 그리고 kernel 함수 내에서 grid에 속한 블록의 최댓값을 알고 싶을 수 있는데, 바로 이때 사용하는 내부 변수가 gridDim입니다.
즉, dim3 grid(2,3)으로 구동한 경우 kernel 함수 내에서 각각의 block 차원 수를 다음과 같이 구할 수 있습니다.
__global__ void kernel()
{
int maxBlockX = gridDim.x; // 2
int maxBlockY = gridDim.y; // 3
}
대개의 경우 gridDim이 사용되는 사례는, 지정된 블록의 수보다 많은 요소의 데이터를 다룰 때입니다. 가령, 100개의 byte 배열에 있는 값을 2개의 블록을 이용해 전체 배열의 값을 +1 하고 싶은 경우 다음과 같이 gridDim을 사용할 수 있습니다.
kernel<<2, 1>>>(buf);
__global__ void kernel(BYTE *srcPtr)
{
int taskId = blockIdx.x;
while (taskId < 100)
{
srcPtr[taskId] = srcPtr[taskId] + 1;
taskId = taskId + gridDim.x; // gridDim.x == 2
}
}
위의 경우, blockIdx.x == 0번인 block이 구동되면 while 문을 통해 0, 2, 4, 6, 8, ...에 해당하는 버퍼의 값을 변경하게 됩니다. 반면 blockIdx.x == 1번인 경우 1, 3, 5, 7, 9, ...에 해당하는 버퍼의 값을 바꿔 [0, 100) 범위의 모든 BYTE 요소를 접근하게 됩니다.
block에 대해 다뤘으니, 이제 thread에 대해 알아볼 차례입니다. kernel 함수 구동에서 두 번째 인자로 전달하는 수가 바로 block 당 구동되는 스레드의 수입니다. 가령, 다음의 kernel 구동은,
kernel<<2, 3>>>();
2개의 커널 복사본(block)이 할당되고, 각각의 block에 대해 3개의 스레드가 실행하는 것으로 이렇게 되면 작업이 총 6개가 됩니다.
block에 대해 몇 번째 스레드가 구동되는지는 내부 변수인 threadIdx를 통해 가능합니다. 따라서 6개의 요소를 가진 배열의 값을 +1 하고 싶다면 다음과 같이 커널 함수를 만들 수 있습니다.
kernel<<1, 6>>>(buf);
__global__ void kernel(BYTE *srcPtr)
{
int taskId = threadIdx.x;
srcPtr[taskId] = srcPtr[taskId] + 1;
}
block의 수를 gridDim 내부 변수로 구할 수 있었던 것처럼, block 당 스레드 수 역시 내부 변수가 제공되는데 그것이 바로 blockDim입니다. blockDim이 사용되는 사례도 gridDim과 유사합니다. 즉, 생성된 스레드보다 많은 요소의 데이터를 접근할 때인데 가령 위의 예제 코드에서 전달되는 buffer의 요소가 총 12개라면 이에 대해 +1을 하기 위해 다음과 같이 blockDim을 활용할 수 있습니다.
kernel<<1, 6>>>(buf);
__global__ void kernel(BYTE *srcPtr)
{
int taskId = threadIdx.x;
while (taskId < 12)
{
srcPtr[taskId] = srcPtr[taskId] + 1;
taskId = taskId + blockDim.x; // blockDim.x == 6
}
}
위의 커널 코드는 1개의 블록으로 6개의 스레드가 실행되고 있기 때문에 각각의 스레드는 다음과 같이 taskId가 while 루프를 통해 증가하면서 작업을 처리합니다.
thread 0: 0, 6
thread 1: 1, 7
thread 2: 2, 8
thread 3: 3, 9
thread 4: 4, 10
thread 5: 5, 11
참고로 블록 당 지정 가능한 스레드의 최대 수는 cudaGetDeviceProperties로 구할 수 있습니다. (cudaDeviceProp.maxThreadsPerBlock, cudaDeviceProp.maxThreadsDim[3])
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
따라서 위의 상황에서 다음과 같은 커널은 정상적으로 구동되지만,
dim3 threads(1, 512, 2); // 1 * 512 * 2 = 1024
kernel <<<1, threads>>>();
1024를 넘기면 cudaErrorInvalidConfiguration 오류가 발생합니다.
dim3 threads(1, 512, 3); // 1 * 512 * 3 = 1536
kernel <<<1, threads>>>();
cudaError_t cudaStatus = cudaGetLastError(); // cudaErrorInvalidConfiguration
지금까지의 예제에서는 block 또는 thread의 한 쪽을 1로 설정했었는데, 그렇지 않은 경우를 보겠습니다.
kernel <<<2, 2>>>();
위의 커널은 2개의 블록에 대해 각각 2개의 스레드로 실행됩니다. 이런 경우 kernel 함수 내에서 작업 ID는 다음과 같이 구할 수 있습니다.
__global__ void kernel()
{
int taskId = threadIdx.x + blockIdx.x * blockDim.x;
}
계산해 보면 다음과 같이 [0, 3]까지의 작업 id가 구해지는 것을 확인할 수 있습니다.
thread\block 0 1
0 0 + 0 * 2 = 0 0 + 1 * 2 = 2
1 1 + 0 * 2 = 1 1 + 1 * 2 = 3
따라서 위의 작업 id와 같은 인덱싱 방식으로 4개의 요소를 가진 데이터를 병렬 처리할 수 있습니다. 그 이상의 데이터, 예를 들어 10개의 요소를 가진 배열을 처리하고 싶다면 다음과 같이 gridDim 내부 변수를 함께 사용하면 됩니다.
__global__ void kernel(BYTE *srcPtr)
{
int taskId = threadIdx.x + blockIdx.x * blockDim.x;
while (taskId < 10)
{
srcPtr[taskId] = srcPtr[taskId] + 1;
taskId = taskId + (blockDim.x * gridDim.x); // (blockDim.x = 2, gridDim.x = 2) == 4
}
}
그럼, 블록 별 스레드에 대한 인덱싱은 다음과 같이 바뀌면서 작업을 처리하게 됩니다.
// 첫 번째 루프
thread\block 0 1
0 0 + 0 * 2 = 0 0 + 1 * 2 = 2
1 1 + 0 * 2 = 1 1 + 1 * 2 = 3
// 두 번째 루프
thread\block 0 1
0 4 6
1 5 7
// 세 번째 루프
thread\block 0 1
0 8 (루프탈출)
1 9 (루프탈출)
점점 더 복잡해지죠? ^^ 게다가 block과 thread에 대해 2차원 이상으로 늘릴 수도 있으니... 연산이 정확한지 신중을 기해 살펴봐야 합니다.
참고로,
예제로 배우는 CUDA 프로그래밍에 언급된 것에 의하면, 어떤 성능 측정의 경우 블록의 수가 멀티 프로세서 수의 정확히 2배가 되었을 때 최고의 성능을 발휘한다고 합니다. 그럼, cudaGetDeviceProperties로 MP 값(cudaDeviceProp.multiProcessorCount)을 구한 후,
(15) Multiprocessors, (128) CUDA Cores/MP: 1920 CUDA Cores
15 * 2 = 30 정도의 값이 블록의 수로 적당하다는 이야기가 됩니다. 그런데 아쉽게도 블록 당 스레드의 적절한 값에 대해서는 언급이 없는데요. 일단 GPU는,
Maximum number of threads per multiprocessor: 2048
라고 cudaGetDeviceProperties를 통해 MP 당 지원가능한 스레드의 수(cudaDeviceProp.maxThreadsPerMultiProcessor)를 구할 수 있습니다. 따라서 위의 경우에는, 15 * 2048 = 30,720개의 동시 스레드를 제공할 수 있다는 것이 됩니다. 물론, 블록 당 최대치는 cudaDeviceProp.maxThreadsPerBlock으로 정해집니다. 아마도 스레드의 적절한 수는 로직에 따라 성능 테스트를 하고 결정하는 것이 좋을 듯 합니다.
자, 그럼 정리해 볼까요? ^^
우선, 여러분은 CUDA에게 grid 하나를 정의해야 합니다. grid는 1 ~ 3차원 block들의 묶음입니다. 그리고 개별 block들에서는 자신의 인덱스를 blockIdx 내부 변수로 알아낼 수 있고 grid의 크기를 gridDim 내부 변수를 통해 접근할 수 있습니다.
또한 하나의 block들은 1 ~ 3차원 thread들의 컨테이너 역할을 합니다. 개별 thread들에서는 자신의 인덱스를 threadIdx 내부 변수로 알아낼 수 있고 block이 소유한 스레드의 크기를 blockDim 내부 변수를 통해 접근할 수 있습니다.
이들을 한데 엮어서 그림으로 표현하면 아래와 같습니다.
[Grid of Thread Blocks - 출처:
http://docs.nvidia.com/cuda/cuda-c-programming-guide/]
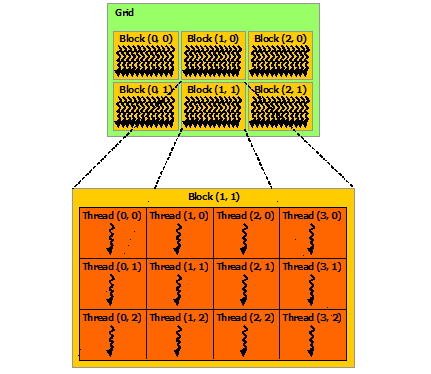
사실 제가 혼란스러웠던 것이 gridDim, blockDim 변수명입니다. 차라리 다음과 같이 이름 지었으면,
gridDim => blockDim
blockDim => threadDim
더 잘 이해가 되었을지도 모르겠습니다
참고로, CUDA 메모리에 관련된 값도 좀 알아볼까요? 우선 cudaGetDeviceProperties를 통해 알아낼 수 있는 정보는 다음과 같습니다. (cudaDeviceProp.totalGlobalMem)
Total amount of global memory: 4096 MBytes (4294967296 bytes)
Maximum memory pitch: 2147483647 bytes
cudaMalloc에 4GB(4294967295)를 전달하면 cudaErrorMemoryAllocation(2) 오류가 반환됩니다. 그럴 수 있습니다, 왜냐하면 다른 프로그램에서도 사용하고 있을 것이기 때문에 4GB가 온전히 남아 있을 리는 없기 때문입니다. CUDA의 가용 메모리는 cudaMemGetInfo 함수를 통해 알아낼 수 있습니다.
cudaMemGetInfo
; https://www.cs.cmu.edu/afs/cs/academic/class/15668-s11/www/cuda-doc/html/group__CUDART__MEMORY_gd5d6772f4b2f3355078ecd6059e6aa74.html
재미있는 것은, 가용 메모리 내에서 1 ~ 3GB를 cudaMalloc으로 메모리를 할당받는 것과 cudaMemcpy 시에 cudaMemcpyHostToDevice 옵션으로 이동하는 것은 잘 되지만, cudaMemcpyDeviceToHost 단계에서는 cudaErrorLaunchFailure(4)가 떨어진다는 점입니다. (원인은 잘 모르겠습니다. 혹시 아시는 분 덧글 부탁드립니다.)
따라서 (4GB 정도의 GPU 메모리 환경에서) GB 단위의 메모리 할당은 현실적으로 피하는 것이 좋겠습니다.
할당에 성공만 한다면 256MB (268,435,456) 정도의 버퍼를 다룬다고 했을 때, GPU block의 수가 2,147,483,647까지 가능하기 때문에 kernel 함수 내부에서 별도의 루프 없이 연산할 수 있습니다. 따라서 메모리에 대한 인덱스를 blockIdx.x만으로 설정하는 것이 가능합니다.
__global__ void incrementArray(BYTE *srcPtr) // BYTE srcPtr[1024 * 1024 * 256];
{
int taskId = blockIdx.x;
srcPtr[taskId] = srcPtr[taskId] + 1;
}
물론 위에서도 언급했지만 이상적인 블록의 수는 MP의 두 배이기 때문에 2147483647로 지정하는 경우가 많지는 않을 것입니다. 단지, 커널 프로그램을 직관적으로 쉽게 다루고 싶다면 저것도 하나의 방법이 될 수 있는 정도입니다.
CUDA의 block과 thread를 이해했다면 이제 __shared__ 예약어로 지정한 공유 메모리도 이해할 수 있습니다.
__shared__ 메모리는 block 단위로 할당된 메모리이므로, block 당 생성되는 thread들에 의해 공유가 되고 서로 다른 block 간에는 공유되지 않는 메모리입니다. 참고로 cudaGetDeviceProperties로 블록 당 공유 메모리의 최댓값(cudaDeviceProp.sharedMemPerBlock)을 구할 수 있습니다.
Total amount of shared memory per block: 49152 bytes
또한 상수 메모리(cudaDeviceProp.totalConstMem)가 있는데,
Total amount of constant memory: 65536 bytes
CUDA에서는 Warp라는 단위로 32개의 스레드를 관리하는데, 그것의 절반인 half-warp, 즉 16개로 관리되는 스레드 중의 하나가 상수 메모리에 읽기 요청을 하는 경우 캐시가 되어 같은 half-warp에 속하는 또 다른 스레드들이 연이어 읽기 요청을 하는 경우 일기 속도가 향상이 됩니다. 이론적으로는 전역 메모리를 사용하는 경우보다 16분의 1까지 읽기 성능이 나아질 수 있습니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]