파이썬 - 윈도우 환경에서 directml을 이용한 tensorflow의 AMD GPU 사용 방법
다음의 글을 보면,
Tensorflow AMD GPU로 학습 방법 - Ubuntu 설치, ROCm 설치,...
; https://yhu0409.tistory.com/14
우분투에 설치하는 글이 나오고 윈도우는 지원이 안 된다고 합니다. 2021년 5월에 쓰인 글인데, 유튜브에 보면 2020년 11월에 올라온 동영상에는 그 방법이 나옵니다.
Tensorflow on AMD GPU with Windows 10
; https://youtu.be/gjVFH7NHB9s
Enable TensorFlow with DirectML on Windows
; https://learn.microsoft.com/en-us/windows/ai/directml/gpu-tensorflow-windows
[관심 있다면!]
Machine Learning for C++ developers - the hard way: DirectML
; https://www.codeproject.com/Articles/5380834/Machine-Learning-for-Cplusplus-developers-the-hard
위의 링크를 정리해 보면, tensorflow-directml을 설치하는 것으로 끝납니다.
pip install tensorflow-directml
그런데, "pip install tensorflow" 명령의 수행으로 이미 2.6.0 버전이 설치된 상태에서 tensorflow-directml을 설치하면 이런 오류가 마지막에 발생합니다.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.6.0 requires gast==0.4.0, but you have gast 0.2.2 which is incompatible.
tensorflow 2.6.0 requires h5py~=3.1.0, but you have h5py 2.10.0 which is incompatible.
tensorflow 2.6.0 requires numpy~=1.19.2, but you have numpy 1.18.5 which is incompatible.
tensorflow 2.6.0 requires tensorboard~=2.6, but you have tensorboard 1.15.0 which is incompatible.
tensorflow 2.6.0 requires tensorflow-estimator~=2.6, but you have tensorflow-estimator 1.15.1 which is incompatible.
Successfully installed astor-0.8.1 gast-0.2.2 h5py-2.10.0 keras-applications-1.0.8 numpy-1.18.5 tensorboard-1.15.0 tensorflow-directml-1.15.5.dev210429 tensorflow-estimator-1.15.1
그러니까, tensorflow-directml의 설치로 tensorflow 1.15.x 버전이 설치돼 그에 따른 구성 요소들도 하위 버전으로 마이그레이션이 된 것입니다. 따라서 오류 메시지이긴 해도 1.15 버전으로는 동작합니다. 실제로 파이썬에서 tensorflow 버전을 확인해 보면,
import tensorflow as tf
print(tf.__version__) # 출력 결과: 1.15.5
2.6.0이 아닌 1.15.5가 나옵니다. 이로 인해 2.6.0에서 지원하는 지난
NVidia 때의 예제 코드는,
import tensorflow as tf
# 실행 오류: AttributeError: module 'tensorflow._api.v1.config' has no attribute 'list_physical_devices'
print(tf.config.list_physical_devices('GPU'))
오류가 발생하므로 이전 세대의 API로 GPU 장치 여부를 알 수 있습니다.
import tensorflow as tf
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
print('gpu: ', tf.test.is_gpu_available())
그럼 다음과 같은 출력 결과를 얻을 수 있습니다.
2021-08-22 23:10:22.322125: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2021-08-22 23:10:22.326421: I tensorflow/stream_executor/platform/default/dso_loader.cc:99] Successfully opened dynamic library E:\Python37\lib\site-packages\tensorflow_core\python/directml.adbd007a01a52364381a1c71ebb6fa1b2389c88d.dll
2021-08-22 23:10:22.741777: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:249] DirectML device enumeration: found 2 compatible adapters.
2021-08-22 23:10:22.812302: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:185] DirectML: creating device on adapter 0 (AMD Radeon(TM) Graphics)
2021-08-22 23:10:22.880983: I tensorflow/stream_executor/platform/default/dso_loader.cc:99] Successfully opened dynamic library Kernel32.dll
2021-08-22 23:10:23.190203: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:185] DirectML: creating device on adapter 1 (AMD Radeon RX 5600 XT)
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 4851906337045356533
, name: "/device:DML:0"
device_type: "DML"
memory_limit: 33708560384
locality {
}
incarnation: 7863706513421206594
physical_device_desc: "{\"name\": \"AMD Radeon(TM) Graphics\", \"vendor_id\": 4098, \"device_id\": 5686, \"driver_version\": \"27.20.1020.1\"}"
, name: "/device:DML:1"
device_type: "DML"
memory_limit: 5595082752
locality {
}
incarnation: 9853096764595565505
physical_device_desc: "{\"name\": \"AMD Radeon RX 5600 XT\", \"vendor_id\": 4098, \"device_id\": 29471, \"driver_version\": \"27.20.22001.14011\"}"
]
gpu: True
어쨌든 되긴 하는데, 이걸 좋아해야 할지 모르겠군요. ^^; tensorflow 1.15.5 버전이라니, NVidia는 2.6.0 버전인데. 그래도 재미있는 점은 아래의 메시지입니다.
I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
지난
NVidia의 경우에는 AVX, AVX2를 모두 지원하지 않는다고 했는데 이번에는 적어도 AVX까지는 지원하는 듯합니다.
directml을 사용하는 경우 기타 환경 구성을 잘 확인하는 것이 좋겠습니다.
microsoft/tensorflow-directml
; https://github.com/microsoft/tensorflow-directml#system-requirements
위의 문서에 보면 directml은 Python 3.8 이상의 최신 버전을 지원하지 않습니다. 실제로 3.8 이상에서 설치를 시도하면 다음과 같은 오류가 발생합니다.
ERROR: Could not find a version that satisfies the requirement tensorflow-directml (from versions: none)
ERROR: No matching distribution found for tensorflow-directml
WARNING: You are using pip version 20.2.1; however, version 21.2.4 is available.
You should consider upgrading via the 'E:\Python38\python.exe -m pip install --upgrade pip' command.
direcml의 로드맵을 보면,
Future and TensorFlow 2
; https://github.com/microsoft/tensorflow-directml/wiki/Roadmap#future-and-tensorflow-2
1.15 버전의 tensorflow를 아직 100% 지원하지 않은 것으로 보입니다. 어쨌든 해당 버전을 확실하게 마무리하면 이후 2.x으로 넘어갈 계획은 있는 것으로 보이는데... 글쎄요. 이건 그때 가봐야 알 듯합니다. ^^
그나저나 제가 가진 머신이,
2020년 작업 PC ^^
; https://www.sysnet.pe.kr/0/0/522
GPU를 소유한 AMD CPU와 Radeon GPU가 함께 있는 것이었습니다. 그리고 기본적으로, tensorflow는 인식한 GPU 중 낮은 ID를 선택하기 때문에,
Use a GPU
; https://www.tensorflow.org/guide/gpu
Using a single GPU on a multi-GPU system
If you have more than one GPU in your system, the GPU with the lowest ID will be selected by default.
이런 경우, tensorflow 파이썬 코드를 그냥 실행하면 아래와 같이 CPU 측의 AMD GPU가 선택되어 돌아갑니다.
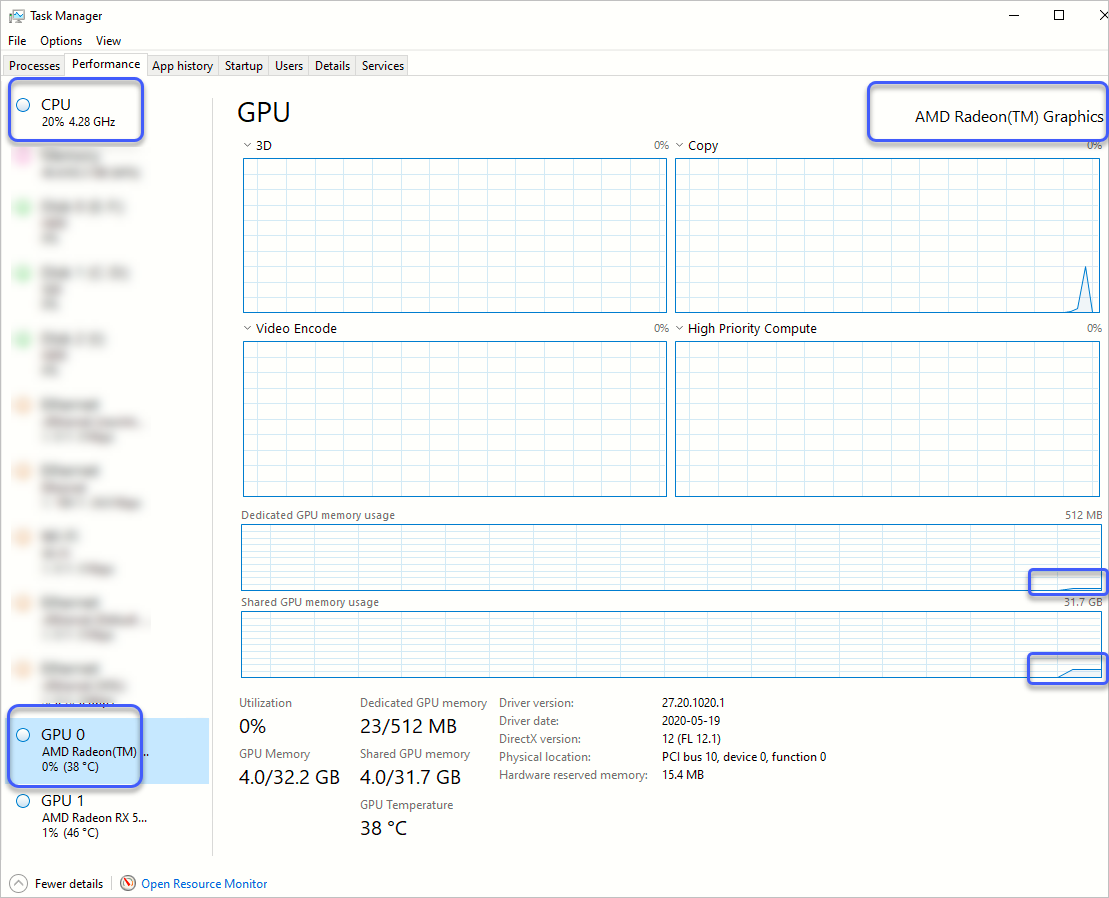
검색해 보면, parallel_model 등을 사용하면 2개 모두 사용할 수 있다고도 하는데요,
model = Sequential()
model.add(Dense(20, input_dim=2, activation='relu'))
model.add(Dense(10,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
parallel_model = multi_gpu_model(model, gpus=2)
아쉽게도 multi_gpu_model은 NVidia 전용이라 Radeon에서는 다음과 같은 오류가 발생합니다.
ValueError: To call `multi_gpu_model` with `gpus=2`, we expect the following devices to be available: ['/cpu:0', '/gpu:0', '/gpu:1']. However this machine only has: ['/cpu:0', '/dml:0', '/dml:1']. Try reducing `gpus`.
여기서 재미있는 것은, direct-ml의 경우 "GPU"로 시작하는 식별자를 갖지 않고 "DML"로 시작한다는 것입니다.
그렇다면, 일단 다중 GPU가 안 되더라도 GPU 선택은 가능해야 하는데 이에 대해서는 다음의 글에서 자세하게 설명하고 있습니다.
FAQ for TensorFlow with DirectML Package
; https://learn.microsoft.com/en-us/windows/ai/directml/gpu-faq
따라서, 0번 인덱스로 시작해 제 컴퓨터의 경우처럼 2번째 GPU가 실제 외장 그래픽 카드인 경우 다음과 같이 환경 변수를 초기에 설정하고 시작하면 됩니다.
# NVidia의 경우
# os.putenv('CUDA_VISIBLE_DEVICES', '1')
# Radeon의 경우
os.putenv('DML_VISIBLE_DEVICES', '1')
위와 같이 하고 다시 tensorflow 관련 코드를 실행하면 다음과 같은 결과를 볼 수 있습니다.
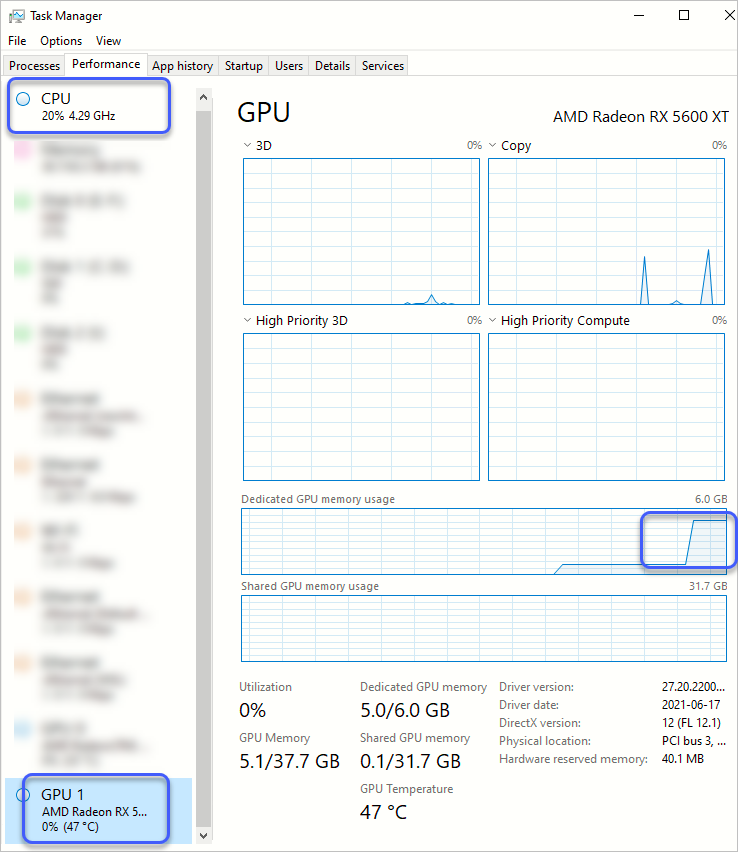
tensorflow API가 1.15 버전으로 낮아지면서 몇몇 코드가 달라지는 것을 고려해야 합니다. 가령
지난 글의 NVidia용 예제 코드를 동일하게 AMD - directml 환경에서 실행해 보면 이런 오류가 발생합니다.
Traceback (most recent call last):
File "D:/pycharm/work/testconsole/main.py", line 74, in <module>
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
KeyError: 'accuracy'
즉, 학습된 history 데이터를 가져오는 과정에서,
loss_ax.plot(hist.history['loss'], 'y', label='train_loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
acc_ax.plot(hist.history['val_accuracy'], 'g', label='val acc')
accuracy와 val_accuracy 필드 이름이 다르기 때문에 다음과 같이 변경해야 합니다.
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
acc_ax.plot(hist.history['val_acc'], 'g', label='val acc')
또 한 가지 재미있는 점이라면, AMD GPU가 달린 컴퓨터는 (NVidia의 경우 i5-4670이었지만) Ryzen 7 PRO 4750G였는데 역시나 CPU가 좋아서 학습 시간도 (26초에서 18초로) 8초 줄었습니다.
...[생략]...
Epoch 5/200
200/200 [==============================] - 0s 402us/sample - loss: 0.5510 - acc: 0.7200 - val_loss: 0.5340 - val_acc: 0.7600
Epoch 6/200
200/200 [==============================] - 0s 402us/sample - loss: 0.5325 - acc: 0.7250 - val_loss: 0.5201 - val_acc: 0.7650
Epoch 7/200
...[생략]...
elapsed: 0:00:18.144820
저런 거 보면, 비록 GPU를 사용하는 tensorflow 버전이라고 해도 CPU와의 협업이 분명 많은 듯합니다. 또한 마찬가지로
지난 글의 MNIST 예제 코드를 실행하면,
GPU 사용: 0:00:59.526554
CPU 사용: 0:01:02.589060
오히려 GPU 성능이 CPU를 앞서기 시작하고,
그보다 더 복잡한 CIFAR10 예제를 테스트해 보면,
// 딥러닝 입문
// ; https://e-koreatech.step.or.kr/page/lms/?m1=course&course_id=170363&m2=course_detail
from datetime import datetime
import os
import tensorflow as tf
import numpy as np
import tensorflow.keras.utils as utils
from tensorflow.keras.datasets import mnist
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
import matplotlib.pyplot as plt
# 두 번째 AMD GPU를 사용하고 싶다면.
# os.environ["DML_VISIBLE_DEVICES"] = "1"
cifar10_data = cifar10.load_data()
((X_train, Y_train), (X_test, Y_test)) = cifar10_data
X_val = X_train[40000:]
Y_val = Y_train[40000:]
X_train = X_train[:40000]
Y_train = Y_train[:40000]
X_train = X_train.reshape(40000, 32 * 32 * 3).astype('float32')
X_val = X_val.reshape(10000, 32 * 32 * 3).astype('float32')
X_test = X_test.reshape(10000, 32 * 32 * 3).astype('float32')
Y_train = utils.to_categorical(Y_train)
Y_val = utils.to_categorical(Y_val)
Y_test = utils.to_categorical(Y_test)
model = Sequential()
model.add(Dense(units=512, input_dim=32*32*3, activation='relu'))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
now = datetime.now()
hist = model.fit(X_train, Y_train, epochs=30, batch_size=32, validation_data=(X_val, Y_val))
print('elapsed: ', datetime.now() - now)
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
print('')
print('loss:', str(loss_and_metrics[0]))
print('accuracy:', str(loss_and_metrics[1]))
각각 다음과 같은 학습 시간을 얻게 됩니다.
CPU: elapsed: 0:03:55.395533
GPU0: elapsed: 0:03:58.814864
GPU1: elapsed: 0:02:19.929523
Radeon 외장형 GPU의 경우 확실히 빨라졌고, CPU와 내장 GPU의 성능이 거의 비슷하게 되었습니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]