System.Drawing.Bitmap 데이터를 Parallel.For로 처리하는 방법
마침, MSDN Forum에 다음과 같은 질문이 올라왔군요.
다음 코드를 병렬화 하려면 어떻게 해야하나요??
; https://social.msdn.microsoft.com/Forums/ko-KR/42957179-fce4-41b5-86ad-44b4720ad401/4579651020-530764630047484-483374714854868-546164714047732?forum=visualcsharpko
이미지에서 Red 값을 제거한 이미지 프로세싱을 하는 간단한 프로그램인데,
Bitmap image1 = new Bitmap(@"d:\image001.jpg", true);
for (int x = 0; x < image1.Width; x++)
{
for (int y = 0; y < image1.Height; y++)
{
Color pixelColor = image1.GetPixel(x, y);
Color newColor = Color.FromArgb(0, pixelColor.G, pixelColor.B);
image1.SetPixel(x, y, newColor);
}
}
실제로 이 로직을 돌려보면, 다음과 같은 결과를 얻을 수 있습니다.

질문자가 원하는 것은, 이 코드를 다중 스레드로 처리하고 싶다는 것입니다. 다행히 처리되는 이미지의 x, y 위치가 독립성이 보장되기 때문에 괜찮은 생각으로 보이는데요. 사실 Parallel.For로 변경하는 것 자체는 다음과 같이 매우 간단하게 이뤄질 수 있지만,
Parallel.For(0, image.Width, x =>
{
Parallel.For(0, image.Height, y =>
{
Color pixelColor = image.GetPixel(x, y);
Color newColor = Color.FromArgb(0, pixelColor.G, pixelColor.B);
image.SetPixel(x, y, newColor);
});
});
애석하게도 다음과 같은 예외가 발생한다는 문제가 있을 뿐입니다. ^^
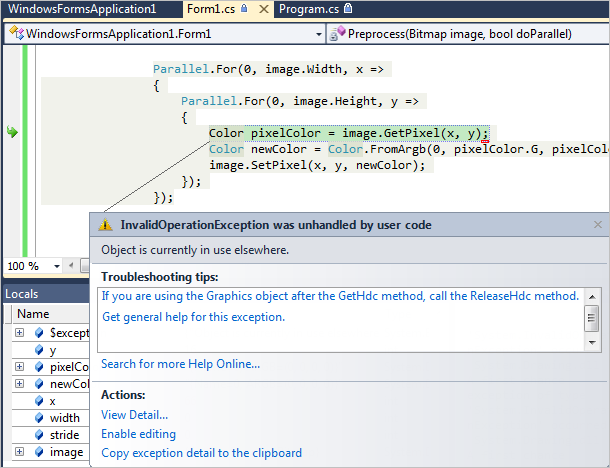
System.InvalidOperationException was unhandled by user code
HResult=-2146233079
Message=Object is currently in use elsewhere.
Source=System.Drawing
StackTrace:
at System.Drawing.Image.get_Width()
at System.Drawing.Bitmap.GetPixel(Int32 x, Int32 y)
at WindowsFormsApplication1.Form1.<>c__DisplayClass5.<>c__DisplayClass7.<Preprocess>b__1(Int32 y) in D:\...[생략]...\WindowsFormsApplication1\Form1.cs:line 68
at System.Threading.Tasks.Parallel.<>c__DisplayClassf`1.<ForWorker>b__c()
InnerException:
위의 예외는 단지 Parallel.For에서만 나타나는 것은 아니고, 다중 스레드에서 해당 Image 개체를 동시에 접근할 때 발생하는 것인데... 아마도 Bitmap 개체의 인스턴스 레벨에서 Thread-safe하지 않아서 발생하는 것 같습니다. 이 상태에서 억지로 예외를 없애려면 Control.Invoke 등의 방법을 사용하거나 동기화를 해야 하는데, 그렇게 되면 다중 스레드를 사용한 의미가 퇴색하게 됩니다.
이 문제를 적절하게 해결하려면, Bitmap 인스턴스 보다는 Bitmap 버퍼를 직접 다루는 것을 고려해 볼 수 있습니다. 다행히, 이에 대해서는 다음의 글에서 방법을 찾아볼 수 있습니다.
Image Processing for Dummies with C# and GDI+ Part 1 - Per Pixel Filters
; http://www.codeproject.com/Articles/1989/Image-Processing-for-Dummies-with-C-and-GDI-Part-1
그래서, Bitmap 버퍼에 대한 포인터를 직접 Parallel.For 루프에 전달해서 처리하면 다음과 같이 풀릴 수 있습니다.
int width = image.Width;
int height = image.Height;
BitmapData bmData = image.LockBits(new Rectangle(0, 0, width, height), ImageLockMode.ReadWrite, PixelFormat.Format24bppRgb);
int stride = bmData.Stride;
System.IntPtr Scan0 = bmData.Scan0;
unsafe
{
byte* p = (byte*)(void*)Scan0;
Parallel.For(0, height, y =>
{
Parallel.For(0, width, x =>
{
int nPos = y * stride + x * 3;
p[nPos + 2] = 0;
});
});
}
image.UnlockBits(bmData);
그럼, 성능 차이가 어느 정도 나는 걸까요? 물론, GetPixel/SetPixel/Color 조작에 따른 함수 부하와 비교해서 버퍼 포인터를 직접 다루는 것 자체도 워낙 성능 차이가 발생하므로 공정하지 않은 결과가 나올 것이라는 것을 쉽게 알 수 있는데요.
다음은 3520 * 1080 이미지에 대해서 테스트한 결과입니다.
Bitmap 직렬 조작: 00:00:53.7462483
버퍼 병렬 조작: 00:00:00.0999150
엄청나군요. ^^;
하지만, 놀라기에는 아직 이릅니다. 지금 놀랬다면, 병렬화가 얼마나 성능에 영향을 미쳤는지를 파악하기 위해 GetPixel/SetPixel/Color 조작을 제거한 직렬 처리를 만들어서 다시 결과를 비교하면 또 놀래야 하기 때문입니다. ^^
버퍼 직렬 조작: 00:00:00.0533465
버퍼 병렬 조작: 00:00:00.0779920
세상에... ^^; 오히려 병렬로 처리했을 때 속도가 더 늦은 것을 볼 수 있습니다. 즉 이전 결과에서의 성능 향상은 단지 버퍼를 직접 액세스하는 차이였을 뿐, 직렬/병렬에 따른 성능 향상은 없었다는 것입니다.
왜 그럴까요? 직렬로 처리한 경우 0.05초 걸리는 작업에서는 오히려 다중 스레드를 관리하는 부하가 더 컸을 수 있다는 결과가 나옵니다. 혹은, 메모리를 산발적으로 접근하는 바람에 cache miss가 더 빈번하게 발생했을 가능성도 있을 것 같고.
어쨌든, 다소 실망스러운 결과죠? ^^
그럼, 병렬 코드로의 변환이 이미지 처리에 그다지 도움되지 않는 걸까요?
100% 그렇다고 볼 수는 없습니다. 왜냐하면, 병렬 처리가 빛이 나는 순간이 있기 때문인데요. 가령, 계산량이 많았을 때 직렬보다 병렬이 더 나은 성능을 보여줄 수 있습니다.
위의 이미지 처리 코드를 gray-scale filter 효과 처리를 위해 다음과 같이 바꿔볼까요?
int nPos = y * stride + x * 3;
blue = p[nPos + 0];
green = p[nPos + 1];
red = p[nPos + 2];
p[nPos + 0] = p[nPos + 1] = p[nPos + 2] = (byte)(.299 * red + .587 * green + .114 * blue);
이전 코드 (p[nPos + 2] = 0)와 비교해서 계산량이 다소 늘어난 상태인데요. 이를 직렬과 병렬로 처리하면 각각 다음과 같은 결과가 나옵니다.
버퍼 직렬 조작: 00:00:00.1406913
버퍼 병렬 조작: 00:00:00.1095246
오호... 이제는 병렬이 0.03초 정도 약간 더 빠르게 바뀌었군요.
좀 더 뚜렷한 결과를 얻기 위해 다음과 같은 오버헤드를 일부러 코드 사이에 넣어보았습니다.
int nPos = y * stride + x * 3;
blue = p[nPos + 0];
green = p[nPos + 1];
red = p[nPos + 2];
p[nPos + 0] = p[nPos + 1] = p[nPos + 2] = (byte)(.299 * red + .587 * green + .114 * blue);
Overhead(0x100);
long Overhead(int x)
{
long sum = 0;
for (int i = 0; i < x; i++)
{
sum += i;
}
return sum;
}
결과는 다음과 같고.
버퍼 직렬 조작: 00:00:06.6304618
버퍼 병렬 조작: 00:00:01.5031154
어떠세요. 감이 오시죠? ^^
그나저나, 이 결과를 보면서 다음의 글이 생각났습니다.
ReaderWriterLockSlim은 언제 쓰는 걸까요?
; https://www.sysnet.pe.kr/2/0/1179
위에서도 단순 작업인 경우 오히려 무조건 잠금을 하는 ex-lock이 sh-lock보다 훨씬 더 좋은 성능을 보여주었는데, 직렬/병렬 처리와 유사한 문제점을 보여주고 있습니다.
테스트한 것처럼, 병렬이 무조건 직렬보다 빠른 것은 아닙니다. 물론, 그 반대의 경우도 아니고. 따라서, 자신의 상황에 맞게 적절한 성능 테스트를 해보고 적용을 해보는 것이 무엇보다 중요합니다.
첨부 파일은 위의 코드를 포함한 간단한 프로젝트입니다. (위의 테스트 수치에 대한 테스트 환경은 i7 CPU가 장착된 노트북으로 여러분들이 직접 실행해 보는 경우 위의 결과값들이 다소 다를 수 있습니다. 또한 모든 테스트 결과는 JIT 컴파일 시간을 측정 시간에서 없애기 위해 미리 한 번 더 호출된 상태입니다.)
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]