무시할 수 없는 Visual C++ 런타임 함수 성능
아래의 글에 달린 덧글 덕분에,
보이어-무어(Boyer-Moore) 알고리즘이 정말 빠를까?
; https://www.sysnet.pe.kr/2/0/1705
C 런타임 함수를 새롭게 보게 되었습니다. ^^
위의 글에서 strstr 함수가 boyer_moore 함수에 비해 굉장히 빠른 속도를 내는 것을 보았는데요. 덧글의 의견처럼 "C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\crt\src\strstr.c"에 해당하는 소스코드는 Visual C++에서 실행되는 strstr 함수가 아니었습니다.
이를 확인하는 방법은 간단합니다.
Visual C++ 프로젝트에서 "Runtime Library" 옵션을 "Multi-threaded Debug"로 바꾸고,
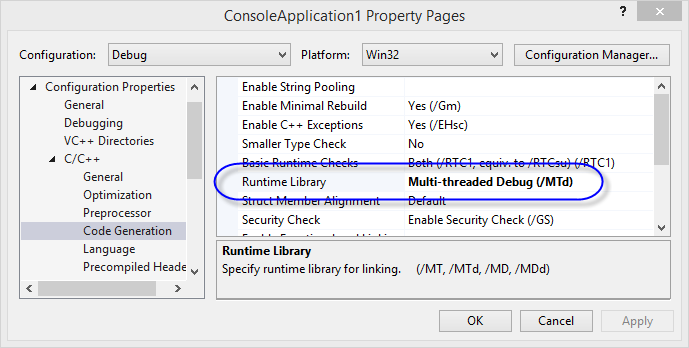
Visual Studio에서 디버깅을 시작한 다음 strstr 함수로 F11(Step-into)키를 눌러 진입하면 다음과 같이 소스 코드를 찾는 창이 뜹니다.
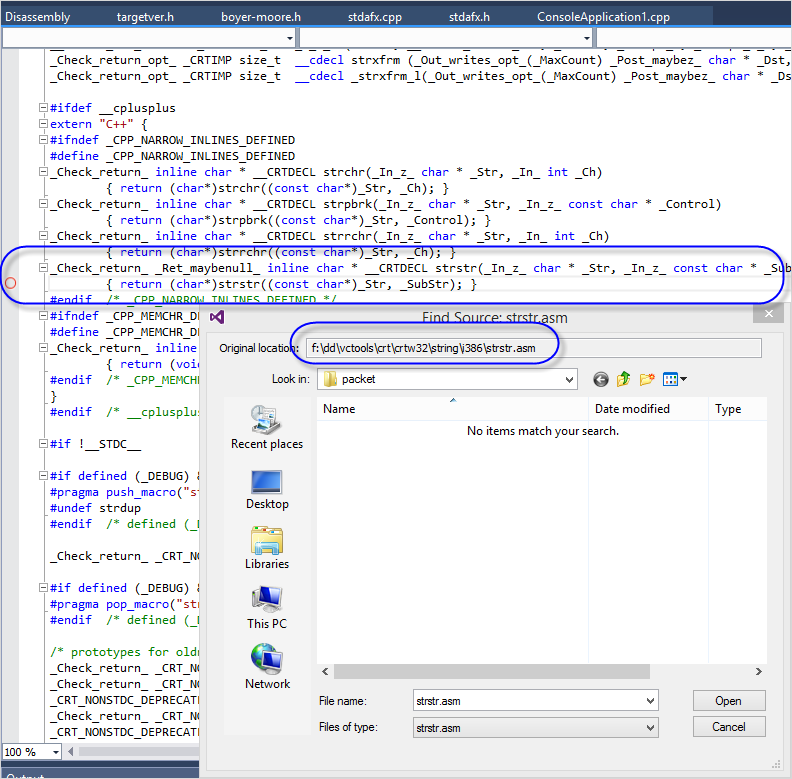
"f:\dd\vctools\crt\crtw32\string\i386\strstr.asm" 경로는 마이크로소프트 측에서 빌드했을 때의 경로이고, 우리는 그냥 strstr.asm 파일을 찾아서 매핑시켜주면 됩니다. Visual Studio 2013을 설치한 경우 다음의 경로에 있으니,
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\crt\src\intel\strstr.asm
이 파일을 맞춰주면 Visual Studio에서 assembly 코드에 대한 라인 단위 디버깅으로 진입합니다. 거기다, "Registers" 창을 띄워 놓으면 레지스터 값 확인까지 가능합니다. 이렇게!
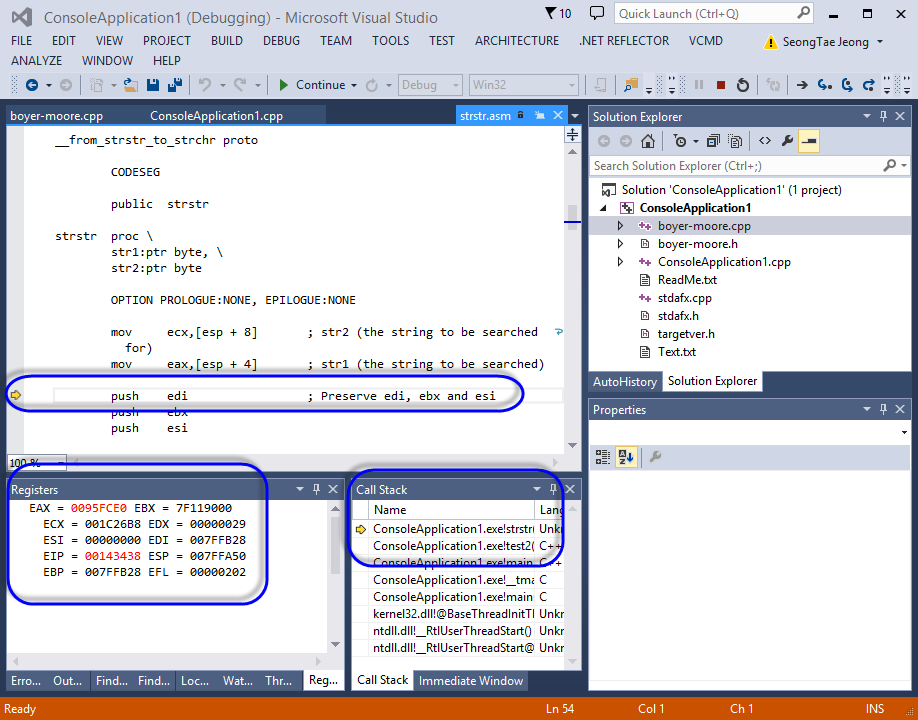
참고로, strstr.asm의 소스 코드는 다음과 같습니다.
page ,132
title strstr - search for one string inside another
;***
;strstr.asm - search for one string inside another
;
; Copyright (c) Microsoft Corporation. All rights reserved.
;
;Purpose:
; defines strstr() - search for one string inside another
;
;*******************************************************************************
.xlist
include cruntime.inc
.list
page
;***
;char *strstr(str1, str2) - search for str2 in str1
;
;Purpose:
; finds the first occurrence of str2 in str1
;
;Entry:
; char *str1 - string to search in
; char *str2 - string to search for
;
;Exit:
; returns a pointer to the first occurrence of string2 in
; string1, or NULL if string2 does not occur in string1
;
;Uses:
;
;Exceptions:
;
;*******************************************************************************
__from_strstr_to_strchr proto
CODESEG
public strstr
strstr proc \
str1:ptr byte, \
str2:ptr byte
OPTION PROLOGUE:NONE, EPILOGUE:NONE
mov ecx,[esp + 8] ; str2 (the string to be searched for)
mov eax,[esp + 4] ; str1 (the string to be searched)
push edi ; Preserve edi, ebx and esi
push ebx
push esi
; .FPO (cdwLocals, cdwParams, cbProlog, cbRegs, fUseBP, cbFrame)
.FPO ( 0, 2, $-strstr, 3, 0, 0 )
; Include SSE2/SSE4.2 code paths for platforms that support them.
include strstr_sse.inc
mov dl,[ecx] ; dl contains first char from str2
mov edi,eax ; str1 (the string to be searched)
test dl,dl ; is str2 empty?
jz empty_str2
mov dh,[ecx + 1] ; second char from str2
test dh,dh ; is str2 a one-character string?
jz strchr_call ; if so, go use strchr code
; length of str2 is now known to be > 1 (used later)
; dl contains first char from str2
; dh contains second char from str2
; edi holds str1
findnext:
mov esi,edi ; esi = edi = pointers to somewhere in str1
mov ecx,[esp + 14h] ; str2
;use edi instead of esi to eliminate AGI
mov al,[edi] ; al is next char from str1
add esi,1 ; increment pointer into str1
cmp al,dl
je first_char_found
test al,al ; end of str1?
jz not_found ; yes, and no match has been found
loop_start:
mov al,[esi] ; put next char from str1 into al
add esi,1 ; increment pointer in str1
in_loop:
cmp al,dl
je first_char_found
test al,al ; end of str1?
jnz loop_start ; no, go get another char from str1
not_found:
pop esi
pop ebx
pop edi
xor eax,eax
ret
; recall that dh contains the second char from str2
first_char_found:
mov al,[esi] ; put next char from str1 into al
add esi,1
cmp al,dh ; compare second chars
jnz in_loop ; no match, continue search
two_first_chars_equal:
lea edi,[esi - 1] ; store position of last read char in str1
compare_loop:
mov ah,[ecx + 2] ; put next char from str2 into ah
test ah,ah ; end of str2?
jz match ; if so, then a match has been found
mov al,[esi] ; get next char from str1
add esi,2 ; bump pointer into str1 by 2
cmp al,ah ; are chars from str1 and str2 equal?
jne findnext ; no
; do one more iteration
mov al,[ecx + 3] ; put the next char from str2 into al
test al,al ; end of str2
jz match ; if so, then a match has been found
mov ah,[esi - 1] ; get next char from str1
add ecx,2 ; bump pointer in str1 by 2
cmp al,ah ; are chars from str1 and str2 equal?
je compare_loop
; no match. test some more chars (to improve execution time for bad strings).
jmp findnext
; str2 string contains only one character so it's like the strchr functioin
strchr_call:
xor eax,eax
pop esi
pop ebx
pop edi
mov al,dl
jmp __from_strstr_to_strchr
;
;
; Match! Return (ebx - 1)
;
match:
lea eax,[edi - 1]
pop esi
pop ebx
pop edi
ret
empty_str2: ; empty target string, return src (ANSI mandated)
mov eax,edi
pop esi
pop ebx
pop edi
ret
strstr endp
end
어셈블리로 최적화된 strstr 함수 말고, C 언어로 된 strstr 함수로 테스트 하는 경우에는 Boyer-Moore 알고리즘이 대체로 빠릅니다.
52KB의 문자열을 준비하고 발견되지 않는 문자열로 10번씩 테스트 해보면,
// x86/Release 빌드
// (낮을 수록 빠릅니다.)
// boyer_moore 검색 시간
boyer_moore (861)
boyer_moore (881)
boyer_moore (979)
boyer_moore (849)
boyer_moore (847)
boyer_moore (865)
boyer_moore (870)
boyer_moore (912)
boyer_moore (853)
boyer_moore (850)
// strstr 검색 시간
strstr (1691)
strstr (1335)
strstr (1320)
strstr (1357)
strstr (1338)
strstr (1296)
strstr (1294)
strstr (1290)
strstr (1291)
strstr (1587)
boyer_moore가 빠릅니다. 1/3 지점 앞 부분에 나오는 약간 긴 텍스트로 검색해 보면,
// boyer_moore 검색 시간
boyer_moore (260)
boyer_moore (31)
boyer_moore (32)
boyer_moore (32)
boyer_moore (42)
boyer_moore (33)
boyer_moore (32)
boyer_moore (31)
boyer_moore (32)
boyer_moore (32)
// strstr 검색 시간
strstr (1345)
strstr (704)
strstr (1498)
strstr (1501)
strstr (403)
strstr (183)
strstr (184)
strstr (183)
strstr (182)
strstr (362)
역시 boyer_moore가 빠릅니다. 뒤에서 1/3 지점에 나오는 짧은 텍스트로 검색을 해보면,
boyer_moore (457)
boyer_moore (431)
boyer_moore (429)
boyer_moore (429)
boyer_moore (430)
boyer_moore (430)
boyer_moore (429)
boyer_moore (430)
boyer_moore (429)
boyer_moore (429)
strstr (213)
strstr (212)
strstr (212)
strstr (212)
strstr (211)
strstr (212)
strstr (340)
strstr (214)
strstr (213)
strstr (213)
이번만큼은 C 언어 함수인 strstr이 빠릅니다.
재미있군요. ^^ strstr C 함수가 사실 굉장히 간단한 편인데도 불구하고 assembly로 최적화했을 때의 속도 향상이 '월등'해지는 것이 꽤나 인상적입니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]