내가 만든 코드보다 OpenCV의 속도가 월등히 빠른 이유
(이 글의 테스트 환경은 i5-4670 4코어, x64로 5760 * 1080 이미지에 대해 처리한 것입니다.)
지난 글에서,
C# - OpenCvSharp 사용 시 C/C++을 이용한 속도 향상 (for 루프 연산)
; https://www.sysnet.pe.kr/2/0/11422
단순 for 루프 연산에 한해 OpenCV가 제공하는 속도를 구현해봤는데요. 사실, 제가 진짜 해보고 싶은 것은 다음의 글에 나온 erode 연산입니다.
OpenCV - 속도 분석 (1)
; https://laonple.blog.me/220861902363
위의 글에 나온 코드를 C# + OpenCvSharp으로 옮겨 보면 다음과 같이 구현됩니다.
static void Convert2(Mat srcMat, Mat kernel)
{
int iMin, iVal;
using (Mat dstMat = srcMat.Clone())
{
for (int i = 0; i < srcMat.Rows - 2; i++)
{
for (int j = 0; j < srcMat.Cols - 2; j++)
{
iMin = 0xFFF;
for (int ii = 0; ii < kernel.Rows; ii ++)
{
for (int jj = 0; jj < kernel.Cols; jj++)
{
if (kernel.At<byte>(ii, jj) != 0)
{
iVal = srcMat.At<byte>(i + ii, j + jj);
if (iMin > iVal)
{
iMin = iVal;
}
}
}
}
dstMat.Set<byte>(i + 1, j + 1, (byte)iMin);
}
}
}
}
놀라운 것은 위의 코드를 실행했을 때 OpenCV로는 10회의 erode 연산을 25ms 안에 완료하는 것을 C#으로는 1회만으로도 26,498ms가 걸린다는 사실입니다. 그나마 Parallel.For를 사용해 바꾸면,
static unsafe int Convert2(Mat srcMat, Mat kernel)
{
using (Mat dstMat = srcMat.Clone())
{
Parallel.For(0, srcMat.Rows - 2, (y) =>)
{
int iMin, iVal;
for (int j = 0; j < srcMat.Cols - 2; j++)
{
iMin = 0xFFF;
for (int ii = 0; ii < kernel.Rows; ii++)
{
for (int jj = 0; jj < kernel.Cols; jj++)
{
if (kernel.At<byte>(ii, jj) != 0)
{
iVal = srcMat.At<byte>(y + ii, j + jj);
if (iMin > iVal)
{
iMin = iVal;
}
}
}
}
dstMat.Set<byte>(y + 1, j + 1, (byte)iMin);
}
});
}
return 0;
}
8초 정도로 떨어지는 데, 이를 10회 반복하면 80초가 넘게 걸립니다. 따라서 erosion/dilation 동작은 C#으로는 구현하지 않는 것이 현명합니다.
재미있는 것은 이제부터입니다. erosion 연산을 C++로 구현하는 경우,
__declspec(dllexport) void erode_cpp_single(BYTE *srcPtr, int srcRows, int srcCols, BYTE *kernelPtr, int kernelRows, int kernelCols, BYTE *dstPtr)
{
int iMin, iVal;
for (int i = 0; i < srcRows - 2; i++)
{
for (int j = 0; j < srcCols - 2; j++)
{
iMin = 255;
for (int ii = 0; ii < kernelRows; ii++)
{
for (int jj = 0; jj < kernelCols; jj++)
{
if (kernelPtr[ii, jj] != 0)
{
iVal = srcPtr[i + ii, j + jj];
if (iMin > iVal)
{
iMin = iVal;
}
}
}
}
dstPtr[i + 1, j + 1] = (BYTE)iMin;
}
}
}
10회 연산을 하면 527ms가 나옵니다. 그리고
지난번처럼 parallel로 바꾸면,
__declspec(dllexport) void erode_cpp_parallel(BYTE *srcPtr, int srcRows, int srcCols, BYTE *kernelPtr, int kernelRows, int kernelCols, BYTE *dstPtr)
{
parallel_for(0, srcRows - 2, [&](size_t srcRow))
{
int iMin, iVal;
BYTE *srcPtrY = srcPtr + (srcRow * srcCols);
BYTE *dstPtrY = dstPtr + (srcRow * srcCols);
for (int j = 0; j < srcCols - 2; j++)
{
iMin = 0xFF;
for (int ii = 0; ii < kernelRows; ii++)
{
for (int jj = 0; jj < kernelCols; jj++)
{
if (*(kernelPtr + (ii * kernelRows + jj)) != 0)
{
iVal = *(srcPtrY + (ii * srcCols + j + jj));
if (iMin > iVal)
{
iMin = iVal;
}
}
}
}
dstPtrY[j] = (BYTE)iMin;
}
});
}
(10회 수행 시) 282ms가 나옵니다. OpenCV의 25ms 수행 시간에 비하면 여전히 10배가 느립니다. 도대체 어디서 이렇게 느린 걸까요? ^^
혹시, 병렬 처리를 더 늘려 보면 될까요? 그래서 2중 for 문이었던 처리를 모두 병렬로 돌려 봤습니다.
__declspec(dllexport) void erode_cpp_parallel2(BYTE *srcPtr, int srcRows, int srcCols, BYTE *kernelPtr, int kernelRows, int kernelCols, BYTE *dstPtr)
{
parallel_for(0, srcRows - 2, [&](size_t srcRow))
{
parallel_for(0, srcCols - 2, [&](size_t srcCol))
{
BYTE *srcPtrY = srcPtr + (srcRow * srcCols);
BYTE *dstPtrY = dstPtr + (srcRow * srcCols);
int iVal;
int iMin = 0xFF;
for (int ii = 0; ii < kernelRows; ii++)
{
for (int jj = 0; jj < kernelCols; jj++)
{
if (*(kernelPtr + (ii * kernelRows + jj)) != 0)
{
iVal = *(srcPtrY + (ii * srcCols + srcCol + jj));
if (iMin > iVal)
{
iMin = iVal;
}
}
}
}
dstPtrY[srcCol] = (BYTE)iMin;
});
});
}
그랬더니, 시간이 좀 왔다 갔다 합니다. 어떤 때는 erode_cpp_parallel에 비해 근소하게 빨랐다가 어떤 때는 느린데, 대체로 30 ~ 100ms 정도 더 느리게 나옵니다. 어쨌든 결과를 봤을 때 분명한 것은 OpenCV는 이런 식으로 처리하지 않는다는 점입니다.
그런데, OpenCV의 저런 처리 속도가 어느 정도 빠른 것인지 감이 안 오실 텐데요. 비교를 위해 erode_cpp_parallel에서 kernel 쪽 루프를 완전히 제거한 경우,
__declspec(dllexport) void erode_cpp_parallel(BYTE *srcPtr, int srcRows, int srcCols, BYTE *kernelPtr, int kernelRows, int kernelCols, BYTE *dstPtr)
{
parallel_for(0, srcRows - 2, [&](size_t srcRow)
{
int iMin, iVal;
BYTE *srcPtrY = srcPtr + (srcRow * srcCols);
BYTE *dstPtrY = dstPtr + (srcRow * srcCols);
for (int j = 0; j < srcCols - 2; j++)
{
iMin = 0xFF;
//for (int ii = 0; ii < kernelRows; ii++)
//{
// for (int jj = 0; jj < kernelCols; jj++)
// {
// if (*(kernelPtr + (ii * kernelRows + jj)) != 0)
// {
// iVal = *(srcPtrY + (ii * srcCols + j + jj));
// if (iMin > iVal)
// {
// iMin = iVal;
// }
// }
// }
//}
dstPtrY[j] = (BYTE)iMin;
}
});
}
실행해 보면 이제서야 속도가 21ms 정도가 나옵니다. 저렇게 아예 처리를 안 하는 정도가 되어야 OpenCV보다 근소하게 빨라지는 것입니다. 어떻게 그럴 수 있는지에 대해서는 다음의 글에서 자세하게 설명하고 있습니다.
OpenCV - 속도 분석 (1)
; http://laonple.blog.me/220861902363
OpenCV - 속도 분석 (6)
; http://laonple.blog.me/220889347089
그렇습니다. 이제 남은 방법은 SIMD입니다. 그리고 이 방법에 대해서는 이미 다음의 글에서 잘 설명하고 있습니다.
SSE - Image Processing
; https://felix.abecassis.me/2012/03/sse-image-processing/
그래도 ^^ 직접 해볼까요? (위의 글에 나오는 코드는 dilation이지만 이 글에서는 erosion으로 해보겠습니다.)
참고로 위의 소스 코드에서는 kernel 처리를 2차원 배열로 하지 않고 1차원으로 처리를 하기 때문에 for 루프가 하나 줄어듭니다. 또한, 코드의 간결함을 위해 일단 kernel의 masking 처리는 제거하고 모두 기본 적용하는 것을 가정하며, 대신 이 글 전체에서 사용한 3*3 커널과 동일한 처리는 합니다. 아래는 이러한 조건들을 반영한 코드입니다.
__declspec(dllexport) void erode_custom(BYTE *srcPtr, int srcRows, int srcCols, BYTE *dstPtr)
{
int width = srcCols;
int height = srcRows;
int step = width;
BYTE *dst = dstPtr;
const BYTE *src = srcPtr;
const int wsize = 9;
const int off[wsize] = { -step - 1, -step, -step + 1,
-1, 0, 1,
step - 1, step, step + 1, };
dst += step;
src += step;
for (int i = 0; i < height - 2; i++)
{
for (int j = 0; j < width - 2; j++)
{
BYTE sup = 0xFF;
for (int k = 0; k < wsize; k++)
{
sup = min(sup, src[j + off[k]]);
}
dst[j] = sup;
}
dst += step;
src += step;
}
}
어쨌든, 이와 같은 방식으로 parallel + SIMD 연산 코드를 적용하면,
__declspec(dllexport) void erode_custom_parallel(BYTE *srcPtr, int srcRows, int srcCols, BYTE *kernelPtr, int kernelRows, int kernelCols, BYTE *dstPtr)
{
int width = srcCols;
int height = srcRows;
int step = width;
BYTE *dst = dstPtr;
const BYTE *src = srcPtr;
const int wsize = 9;
const int off[wsize] = { -step - 1, -step, -step + 1,
-1, 0, 1,
step - 1, step, step + 1, };
parallel_for(1, height - 2, [&](size_t srcRow)
{
BYTE *srcPtrY = srcPtr + (srcRow * srcCols);
BYTE *dstPtrY = dstPtr + (srcRow * srcCols);
for (int j = 0; j < width - 16; j += 16)
{
__m128i m = _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[0]));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[1])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[2])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[3])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[4])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[5])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[6])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[7])));
m = _mm_min_epu8(m, _mm_loadu_si128((const __m128i*)(srcPtrY + j + off[8])));
_mm_storeu_si128((__m128i*)(dstPtrY + j), m);
}
srcPtrY += step;
dstPtrY += step;
});
}
/*
이 소스 코드는 +16씩 진행하기 때문에 마지막 %16 크기만큼의 처리를 더 해줘야 하지만 생략합니다.
게다가 kernel의 mask 처리도 생략된 것입니다.
*/
이제서야 속도가 18ms로 나오면서 OpenCV를 따라잡았습니다. 물론 범용 처리를 하는 OpenCV가 약간의 부가 작업이 있을 테니 당연히 이 정도는 빨라야 합니다. 보는 바와 같이 SIMD 처리가 의외로 막강하다는 것을 체감할 수 있었는데요, 그렇다면 혹시 AVX 256bit로 하면 좀 더 빨라질 수 있을까요?
for (int j = 0; j < width - 32; j += 32)
{
__m256i m = _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[0]));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[1])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[2])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[3])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[4])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[5])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[6])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[7])));
m = _mm256_min_epu8(m, _mm256_loadu_si256((const __m256i*)(srcPtrY + j + off[8])));
_mm256_storeu_si256((__m256i*)(dstPtrY + j), m);
}
아쉽지만 더 빨라지지는 않고 128bit 처리와 거의 동일했습니다. 어쨌든, 이것으로 OpenCV가 왜 빠른지 알 수 있었는데요, 역시 알면 알수록 OpenCV 내의 메서드 호출을 기반으로 구현하는 것이 더 좋은 선택이라는 답이 나옵니다. ^^
(
첨부 파일은 이 글의 소스 코드를 포함합니다.)
이번에도 성능 수치를 엑셀 그래프로 그려봤습니다. ^^ (C#은 너무 느려서 포함시키면 그래프가 왜곡되므로 제외했습니다.)
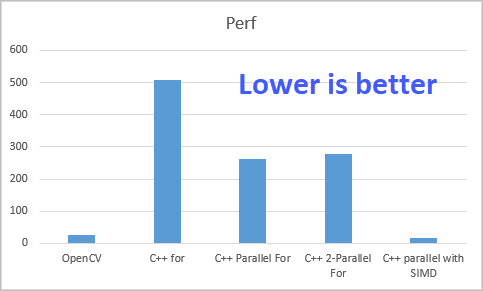
개인적으로 이 글을 쓰면서 느낀 점이 좀 있습니다. 사실 그전에는 parallel 처리라고 해봐야 결국 CPU 자원을 쓰는 것이기 때문에 그다지 매력적이라고 생각지 않았고 SIMD는 다소... 먼 나라 이야기라고 생각했었습니다. 하지만, 이 글을 통해서 parallel + SIMD 처리가 소프트웨어에서 얼마나 강력한 성능을 발휘하는지 실감하게 되었고 현실적으로 충분히 적용할만한 기술로 다가왔습니다. 물론 SIMD 연산이 아무 데나 적용할 수 있는 유형은 아닙니다. 예를 들어
지난번 글에서 예제로 든 RGB -> RGBA 변환과 같은 간단한 유형에도 SIMD 연산은 적용할 수 없는 로직에 속합니다.
그렇긴 하지만, 만약 적용할 수 있었을 때의 성능 향상이 이 정도라면 평소 코딩에서 SIMD 적용 여부에 대한 촉각을 곤두세울만한 가치는 있어 보입니다.
그나저나 이왕 내친김에, GPGPU 연산 쪽 관련 공부도 해봐야겠다는 생각이 듭니다. ^^ 음... 뭐랄까... 게임하면서 강력한 아이템을 하나 얻은 것 같은 기분입니다. ^^
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]