C# - 부동 소수 계산 왜 이렇게 나오죠? (2)
지난번 글에서,
C# - 부동 소수 계산 왜 이렇게 나오죠? (1)
; https://www.sysnet.pe.kr/2/0/10872
약간 부족한 점이 있습니다. 그렇다면 왜 C++ (범위를 좁히겠습니다. Visual Studio 2015의 Visual C++)에서는 2개의 코드 결과값이 모두 13으로 나오느냐는 것입니다.
사실, 이것도 Visual C++로 코드 작성하고 disassembly 창을 통해 생성된 기계어를 보면 알 수 있습니다. 현재 Visual Studio 2015의 C++ 컴파일러는 다음과 같은 기계어를 생성합니다.
float a = 10.0f;
008B17BE movss xmm0,dword ptr ds:[8B6B38h]
008B17C6 movss dword ptr [a],xmm0
float b = 1.3f;
008B17CB movss xmm0,dword ptr ds:[8B6B34h]
008B17D3 movss dword ptr [b],xmm0
int c = (int)(a * b);
008B17D8 movss xmm0,dword ptr [a]
int c = (int)(a * b);
008B17DD mulss xmm0,dword ptr [b]
008B17E2 cvttss2si eax,xmm0
008B17E6 mov dword ptr [c],eax
float a = 10.0f;
00CC167E movss xmm0,dword ptr ds:[0CC6B34h]
00CC1686 movss dword ptr [a],xmm0
float b = 1.3f;
00CC168B movss xmm0,dword ptr ds:[0CC6B30h]
00CC1693 movss dword ptr [b],xmm0
int c3 = (int)(float)(a * b);
00CC1698 movss xmm0,dword ptr [a]
int c3 = (int)(float)(a * b);
00CC169D mulss xmm0,dword ptr [b]
00CC16A2 cvttss2si eax,xmm0
00CC16A6 mov dword ptr [c3],eax
오호... 명령어 셋이 틀리군요. 그건 둘째치고, 보니까 (float) 형변환 했을 때의 기계어와 하지 않았을 때의 기계어가 다르지 않습니다. 일단 이것으로 동일한 결과를 내는 이유가 설명됩니다. C++에서는 (float) 형변환 연산자는 무시해 버리는 것입니다.
하지만 그렇게 해도 괜찮은 이유가 있습니다. 128비트 xmm0 레지스터에 movss 명령어를 통해 4바이트 float 단정도 부동 소수점의 값을 넣고 있는데, 이런 경우 128비트 xmm0 레지스터는 4개의 32비트로 나뉘어 movss에서 지정한 4바이트 메모리 영역으로부터 직접 값을 받아들입니다. 애당초 4바이트로 끝내고 있기 때문에 (float) 형변환 연산자를 굳이 적용해야 할 필요가 없었던 것입니다.
그럼, C#도... 아니 닷넷 JIT 컴파일러도 이렇게 해줬어야 하는 거 아니냐는 의견이 나올 수 있습니다.
여기서 제가 ... ^^; CLR 개발자 측에 실망스러운 것이 하나 발견되었는데요. 원래 CLR의 장점 중 하나가 런타임 시에 해당 컴퓨팅 환경을 보고 그에 맞는 최적의 CPU 기계어를 생성해 준다고 했기 때문입니다.
위의 Visual C++에서 출력된 movss/mulss 명령은 새롭게 SSE(Streaming SIMD Extensions)를 구현한 CPU에서만 지원되는 명령어입니다. 즉, Visual C++는 이것을 적용한 기계어가 생성된 것이고, 반면 닷넷 JIT 컴파일러는 예전의 구형 기계어 명령을 이용한 결과를 출력한 것입니다.
이에 대해서는 몇 가지 더 재미있는 점이 있습니다.
닷넷 JIT 컴파일러는 x86과 x64가 다른데요. 일반적으로 x64가 더 최적화된 결과를 내주는 것으로 알려져 있습니다. 실제로, 문제가 되었던 이번 예제를 x64로 빌드해서 실행해 보면 동일하게 모두 13 값이 나오고 기계어 코드 역시 다음에서 보는 것처럼 SSE를 이용하는 코드를 생성해 줍니다.
// x64 닷넷 JIT 컴파일러가 출력한 기계어
float a = 10f;
00007FF8144F04B6 vmovss xmm0,dword ptr [7FF8144F0518h]
00007FF8144F04BF vmovss dword ptr [rbp+34h],xmm0
float b = 1.3f;
00007FF8144F04C5 vmovss xmm0,dword ptr [7FF8144F051Ch]
00007FF8144F04CE vmovss dword ptr [rbp+30h],xmm0
int c = (int)(a * b); // c == 13
00007FF8144F04D4 vmovss xmm0,dword ptr [rbp+34h]
00007FF8144F04DA vmovss xmm1,dword ptr [rbp+30h]
00007FF8144F04E0 vmulss xmm0,xmm0,xmm1
00007FF8144F04E5 vcvttss2si ecx,xmm0
00007FF8144F04EA mov dword ptr [rbp+2Ch],ecx
int c3 = (int)(float)(a * b); // c3 == 13
00007FF8144F04ED vmovss xmm0,dword ptr [rbp+34h]
00007FF8144F04F3 vmovss xmm1,dword ptr [rbp+30h]
00007FF8144F04F9 vmulss xmm0,xmm0,xmm1
00007FF8144F04FE vcvttss2si ecx,xmm0
00007FF8144F0503 mov dword ptr [rbp+28h],ecx
결과는 Visual C++과 차이가 나지 않습니다.
이런 차이점은 Visual C++에서도 발생합니다. 프로젝트 속성창에서 다음과 같이 SSE를 사용하지 않겠다고 하면,
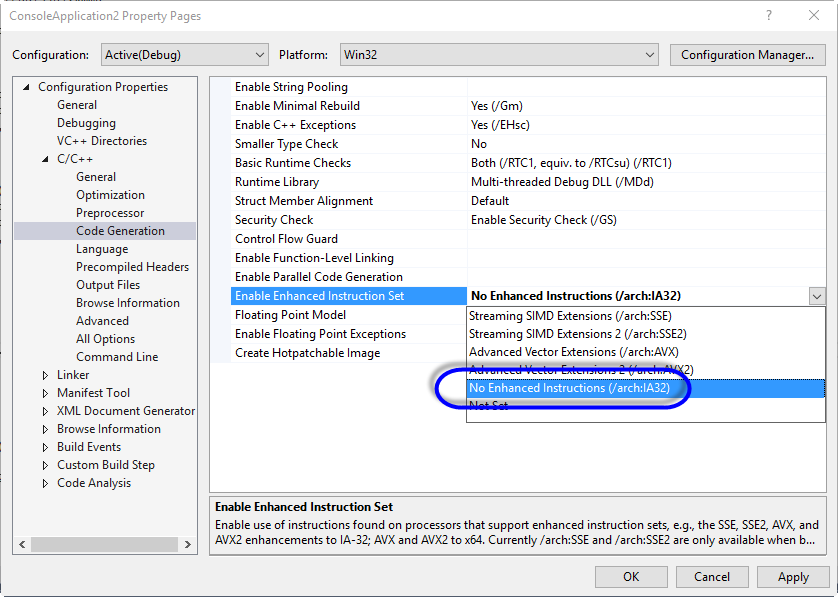
x86 C#에서의 결과와 마찬가지로 12, 13의 값이 나오는 기계어 코드가 생성됩니다.
// Visual C++ - 옵션 설정 No Enhanced Instructions (/arch:IA32)
float a = 10.0f;
009F167E fld dword ptr ds:[9F6B34h]
009F1684 fstp dword ptr [a]
float b = 1.3f;
009F1687 fld dword ptr ds:[9F6B30h]
009F168D fstp dword ptr [b]
int c = (int)(a * b); // c == 12
009F1690 fld dword ptr [a]
009F1693 fmul dword ptr [b]
009F1696 call __ftol2_sse (09F1334h)
009F169B mov dword ptr [c],eax
int c3 = (int)(float)(a * b); // c3 == 13
009F169E fld dword ptr [a]
009F16A1 fmul dword ptr [b]
009F16A4 fstp dword ptr [ebp-0F4h]
009F16AA fld dword ptr [ebp-0F4h]
009F16B0 call __ftol2_sse (09F1334h)
009F16B5 mov dword ptr [c3],eax
그러니까, 부동 소수점 계산은 CPU에 전적으로 의존적이므로 같은 소스코드라도 어떻게 출력될지는 아무도 장담할 수 없습니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]