C# - Azure OpenAI API를 이용해 사용자가 제공하는 정보를 대상으로 검색하는 방법
ChatGPT에 들어가,
ChatGPT
; https://chat.openai.com/
정보를 요청하는 대화를 시작하는 경우, 그 정보의 소스는 사실 대부분 웹 페이지 등에 공개된 것입니다. (게다가, 그 정보를 정리한 시점은 2023-11-22일 기준으로 2022년 1월이라고 합니다.) (2025-06-23 업데이트: 이러한 최신 정보의 답변 기능을 향상하기 위해 OpenAI는 웹 검색 기능을 추가했습니다. 참고:
"GPT API에서 실시간 검색 결과 받기!!(OpenAI의 Web Search Preview)")
이것을 다시 말하면, 사내에 구축된 Knowledge Base 시스템에 있는 정보들은 ChatGPT 입장에서 절대로 알 수 없습니다. 그렇다면, 그런 데이터를 대상으로 질의 시스템을 만들고 싶다면 어떻게 해야 할까요?
이에 대한 답변 역시, ^^ .NET Conf 2023에서 다 나온 내용입니다. 이름하여 "Embedding Search"라고 하는데요,
Build Intelligent Apps with .NET and Azure - Embedding Search
; https://youtu.be/xEFO1sQ2bUc?t=27934
정리하는 차원에서 그대로 베껴 보겠습니다. ^^
자, 그럼 먼저 적당한 데이터 예제를 구해야 하는데요, "
Build Intelligent Apps with .NET and Azure - Embedding Search" 글에서도 예를 들었던 GitHub 이슈를 저도 다뤄보겠습니다. 하지만, 이에 대해서는 저번에 별도의 글로 설명했으니,
C# - Octokit을 이용한 GitHub Issue 검색
; https://www.sysnet.pe.kr/2/0/13450
위의 예제를 돌리면 (여러분의 GitHub Repo를 대상으로 해도 됩니다.) 대략 다음과 같은 식의 issues.json 파일을 구할 수 있을 것입니다.
[
{
"Title": "Increase hold of left click",
"Text": "Hello, thank you for making this project open source. I ran succefully in a raspberry pi zero w. However, I need to hold the left click for around 3-4 seconds. Could you please give a general instruction on how I can achieve this?\r\n\r\nI was trying to add a sleep at the end of MouseDevice::SendRelative function inside the rasp_vusb_server but I\u0027m having some trouble building this project. Could you please inform If I\u0027m in the right path.",
"Url": "https://github.com/stjeong/rasp_vusb/issues/16"
},
// ...[생략]...
]
그렇다면 우선 저 데이터를 로딩해야겠군요. ^^
GitHubIssue[]? issues = await LoadIssuesFromFileAsync("issues.json");
if (issues == null)
{
Console.WriteLine("Failed to load issues.json");
return;
}
public static async Task<GitHubIssue[]?> LoadIssuesFromFileAsync(string fileName)
{
var filePath = Path.Combine("..", "..", "..", fileName);
var text = await File.ReadAllTextAsync(filePath);
return JsonSerializer.Deserialize<GitHubIssue[]>(text);
}
public record GitHubIssue(string Title, string Text, string Url);
이렇게 로딩한 데이터는 단순히 "텍스트" 문자열을 담고 있기 때문에 (단순한 비교를 넘는) 검색을 할 수 없습니다. 즉, 사람이 이해하는 형식의 문자열을 수학으로 이해할 수 있는 형식의 연산 가능한 숫자로 바꿔야 하는데요, 간단하게 말하면 문자열을 숫자 벡터로 바꿔주는 Embedding 과정을 거쳐야 하는 것입니다.
Azure OpenAI로부터 Embedding을 하려면 지난 글에 설명한 것과 같은 방식으로, 즉
Azure Portal의 "Model deployments"로 들어가 "배포"에서 Embedding을 위한 모델을 하나 만들어야 합니다.
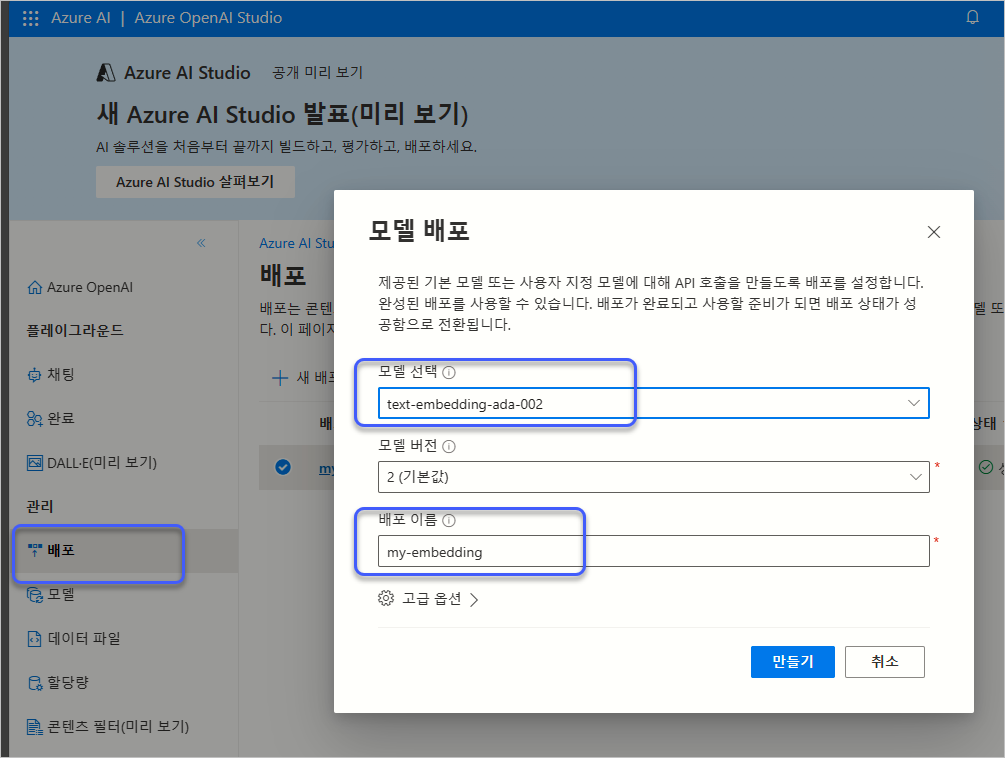
New and improved embedding model
; https://openai.com/blog/new-and-improved-embedding-model
이렇게 생성한 Embedding 모델을 이용해 이제 GitHub 이슈의 텍스트 정보를 벡터로 변환해 줍니다.
// NuGet 참조 추가
// Install-Package Azure.AI.OpenAI -Pre
// Install-Package Microsoft.DotNet.Interactive.AIUtilities -Pre
// Install-Package System.Numerics.Tensors
string azureOpenAIKey = "...[azure openai key]..."; // 초기화 참고
string azureOpenAIEndpoint = "...[azure openai endpoint]...";
var embeddingDeployment = "my-embedding";
GitHubIssue[]? issues = await LoadIssuesFromFileAsync("issues.json");
if (issues == null)
{
Console.WriteLine("Failed to load issues.json");
return;
}
var issuesWithChunksColleciton =
issues.Select(issue => new IssueWithChunks(issue, new()))
.ToArray();
Console.WriteLine(issuesWithChunksColleciton);
var tokenizer = await Tokenizer.CreateAsync(TokenizerModel.ada2);
foreach (var item in issuesWithChunksColleciton)
{
var fullText = item.Issue.Text;
if (string.IsNullOrWhiteSpace(fullText))
{
continue;
}
var chunks = tokenizer.ChunkByTokenCountWithOverlap(fullText, 3000, 50)
.Select(t =>
$"""
Title: {item.Issue.Title}
{t}
""").Chunk(16)
.ToArray();
foreach (var chunk in chunks)
{
var embeddingResponse = await openAIClient.GetEmbeddingsAsync(
new EmbeddingsOptions(embeddingDeployment, chunk));
item.Chunks.AddRange(
embeddingResponse.Value.Data.Select(d =>
new TextWithEmbedding(chunk[d.Index], d.Embedding.ToArray())));
}
}
await SaveIssuesWithChunksToFileAsync(issuesWithChunksColleciton, "issueWithEmbeddingsSubset.json");
public static async Task SaveIssuesWithChunksToFileAsync(IEnumerable<IssueWithChunks> data, string fileName)
{
var filePath = Path.Combine("..", "..", "..", fileName);
var issuesJson = JsonSerializer.Serialize(data, new JsonSerializerOptions(
JsonSerializerOptions.Default)
{ WriteIndented = true });
await File.WriteAllTextAsync(filePath, issuesJson);
}
public record TextWithEmbedding(string Text, float[] Embedding);
public record IssueWithChunks(GitHubIssue Issue, List<TextWithEmbedding> Chunks);
매번 동일한 데이터에 GetEmbeddingsAsync를 호출하면 OpenAI API 사용량만 늘려 비용을 발생시키므로 위의 예제에서는 그 결과를 "issueWithEmbeddingsSubset.json" 파일에 보관하고 있습니다.
이렇게 한번 Embedding 데이터를 구축했으면 이후에는 그 벡터를 활용해 검색하면 되는데요, (
벡터 검색만으로는 충분한가?) 하지만 검색을 위한 문자열도 동일한 Embedding 모델로 벡터 변환을 한 후 검색하는 식으로 코딩을 하면 됩니다.
var embeddingDeployment = "my-embedding"; // Azure AI Studio에서 생성한 배포 이름
OpenAIClient openAIClient = // ...[초기화 코드 생략]...
var issuesWithChunksCollection = await LoadIssuesWithChunksFromFileAsync("issueWithEmbeddingsSubset.json");
string question = "Are there any issues for mouse?";
string[] results = await EmbeddingSearchAsync(openAIClient, embeddingDeployment,
question, issuesWithChunksCollection!, issuesWithChunksCollection.Length);
results.All((text) =>
{
Console.WriteLine(text);
Console.WriteLine("-----------------------------------");
return true;
});
Console.WriteLine($"Found: {results.Length}");
public static async Task<string[]> EmbeddingSearchAsync(OpenAIClient openAIClient,
string embeddingDeployment,
string query, IssueWithChunks[] data, int resultLimit = 1)
{
var embeddingResponse = await openAIClient.GetEmbeddingsAsync(
new EmbeddingsOptions(embeddingDeployment, new[] {query}));
var embeddingVector = embeddingResponse.Value.Data[0].Embedding.ToArray();
var searchResults =
data
.SelectMany(d => d.Chunks)
.ScoreBySimilarityTo(embeddingVector, new SimilarityComparer(), c => c.Embedding)
.OrderByDescending(e => e.Value)
.Where(e => e.Value > 0.5)
.Take(resultLimit)
.Select(e => e.Key.Text)
.ToArray();
return searchResults;
}
public static async Task<IssueWithChunks[]?> LoadIssuesWithChunksFromFileAsync(string fileName)
{
var filePath = Path.Combine("..", "..", "..", fileName);
var text = await File.ReadAllTextAsync(filePath);
return JsonSerializer.Deserialize<IssueWithChunks[]>(text);
}
public class SimilarityComparer : ISimilarityComparer
{
public float Score(float[] a, float[] b)
{
return TensorPrimitives.CosineSimilarity(a, b);
}
}
위의 코드에서는 "Are there any issues for mouse?"라는 질문을 던져 issueWithEmbeddingsSubset.json에 있던 벡터들과
CosineSimilarity를 비교해 연관이 높은 이슈를 반환하는데요, 결과를 보면 16개의 이슈 중 12개를 반환하고 있습니다.
Title: Mouse movement not working with Linux Systems
Hello!
A represent a team of engineers that are enjoying using your application to automate mouse and keyboard on Windows computers. We've discovered that the device doesn't behave similarly when connected to a Linux device (Mouse inputs aren't working). Would you be able to point us in your code where we can begin looking to try to solve this issue on our own? Thanks and take care!
-----------------------------------
...[생략]...
-----------------------------------
Found: 12
대충 흐름이 눈에 들어오시나요? ^^
(
첨부 파일은 이 글의 예제 코드를 포함합니다.)
한 가지 오해하면 안 되는 것이 있는데요, 위에서 예를 든 EmbeddingSearchAsync 함수는 질문에 대해 자연어 분석을 하지는 않는다는 점입니다. 실제로 단순히
TensorPrimitives.CosineSimilarity 함수를 이용한 유사도를 비교한 것에 불과한 것이기 때문에, 질문을 다음과 같이 해도,
string question = "Are there any issues except for mouse?";
string[] results = await EmbeddingSearchAsync(openAIClient, embeddingDeployment,
question, issuesWithChunksCollection!, issuesWithChunksCollection.Length);
// 이전 질문과 동일한 결과 반환 ("except for"를 이해하지 못함)
단순히 "Are", "there", "any", "issues", "except", "for", "mouse"
와 같은 토큰들로 연관 검색을 한 것에 불과합니다. 즉 "except for"에 대한 의미는 반영하지 못한 것입니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]