Win32 API의 A(ANSI) 버전은 DBCS를 사용할까요?
지난 글에서,
Win32 API의 W(유니코드) 버전은 UCS-2일까요? UTF-16 인코딩일까요?
; https://www.sysnet.pe.kr/2/0/13777
Win32 API가 A(ANSI), W(UNICODE) 버전으로 나뉜다고 했습니다. Visual C++의 경우 ANSI 버전은 char(1바이트) 타입으로, UNICODE 버전은 wchar_t(2바이트) 타입으로 표현하는데요, 서로 간의 변환하는 함수도 제공합니다.
물론, 변환에 실패하는 경우도 있습니다. 가령, 유니코드에 있는 한글을
CP1252 코드 페이지의 ANSI 문자열로 변환하면
"?" 글자로 출력이 됩니다.
윈도우 문서를 읽다 보면, 예를 들어, CP949(ks_c_5601-1987)로 설정된 경우 A 버전의 Win32 API를 호출할 때 전달하는 char 문자열을 DBCS라고 설명하는 내용이 나옵니다. 그리고 이런 단어가 나오면 자연스럽게 SBCS, MBCS도 등장하게 되는데요, 이번 글에서는 바로 이들 용어에 대해서 알아보겠습니다. ^^
웹상에 찾아보면 공식 문서를 꽤나 쉽게 찾을 수 있습니다.
SBCS, DBCS, and MBCS data conversion considerations
; https://www.ibm.com/docs/en/cics-tx/10.1.0?topic=conversion-sbcs-dbcs-mbcs-data-considerations
Single-byte Character Sets
; https://learn.microsoft.com/en-us/windows/win32/intl/single-byte-character-sets
Double-byte Character Sets
; https://learn.microsoft.com/en-us/windows/win32/intl/double-byte-character-sets
간단하게 정리해 볼까요? ^^
우선, SBCS는 Single Byte Character Set의 약자로, 한 문자를 표현하는데 1바이트를 사용하는 문자 집합을 의미합니다. 그러니까
Code Page 437, 1252 등의 문자 집합이 SBCS에 해당합니다.
반면, DBCS는 Double Byte Character Set의 약자로,
Double-byte character set
; https://en.wikipedia.org/wiki/Double-byte_character_set
한 문자를 표현하는데 1~2바이트를 사용하는 문자 집합을 의미합니다. 이에 대해 위의 "
SBCS, DBCS, and MBCS data conversion considerations" 문서에도 나오듯이,
- X'00' to X'7F' are single-byte codes
- X'81' to X'9F' are double-byte introducer
- X'A1' to X'DF' are single-byte codes
- X'E0' to X'FC' are double-byte introducer
"
ASCII printable characters" 범위(0x00 ~ 0x7f)의 문자를 표현할 때는 1바이트로 나타내지만, 한자나 한글 등을 표현할 때는 "double-byte introducer"를 선행 바이트로 도입해 2바이트까지 사용합니다. Windows 관련 문서에서는 DBCS에서 "double-byte introducer" 같은 문자를 "lead byte"라고 표현합니다. 실제로, 아래의 함수는,
IsDBCSLeadByte function
; https://learn.microsoft.com/en-us/windows/win32/api/winnls/nf-winnls-isdbcsleadbyte
DBCS 문자열에서 특정 바이트가 lead byte인지를 알려줍니다. DBCS에 속하는 문자셋의 가장 흔한 케이스가 바로 우리 한국어 문자셋 중의 하나인 "ksc_5601-1987"입니다.
KS X 1001
; https://en.wikipedia.org/wiki/KS_X_1001
위의 문서에 보면 우측 "Classification" 필드에 "DBCS" 항목으로 분류하고 있습니다.
이 외에 위키피디아 문서에 보면 TBCS라는 용어도 나옵니다.
A triple-byte character set (TBCS) is a character encoding in which characters (including control characters) are encoded in three bytes
마지막으로, MBCS는 Multi-Byte Character Set의 약자로, 한 문자를 표현하는데 1~n바이트를 사용하는 문자 집합을 의미합니다. 다른 말론 "Variable-width encoding"이라고도 합니다.
Variable-width encoding
; https://en.wikipedia.org/wiki/Variable-width_encoding
위의 문서에 보면 MBCS(뿐만 아니라 SBCS, DBCS)의 "character set" 표현보다 encoding이라는 명칭이 더 정확하다고 언급하는데요,
Most common variable-width encodings are multibyte encodings (aka MBCS – multi-byte character set), which use varying numbers of bytes (octets) to encode different characters. (Some authors, notably in Microsoft documentation, use the term multibyte character set, which is a misnomer, because representation size is an attribute of the encoding, not of the character set.)
개인적으로도 "Multi-Byte
Character Set"이라는 명칭보다는 "Multi-Byte
Character Encoding"이라는 명칭이 더 정확하다고 생각합니다. ^^
암튼, MBCS가 "Variable-width encoding"을 의미하므로 따지고 보면 DBCS도 MBCS의 일종입니다. 그리고 대표적인 MBCS로는 UTF-8이 있는데요,
UTF-8
; https://en.wikipedia.org/wiki/UTF-8
위의 문서에 "Classification"을 보면 "variable-length encoding"으로 분류돼 있습니다. 현재 기준으로는 UTF-8 인코딩은 아래의 방식에 따라 최대 6바이트까지 지원합니다.
// https://www.rfc-editor.org/rfc/rfc2279
UCS-4 range (hex.) UTF-8 octet sequence (binary)
0000 0000-0000 007F 0xxxxxxx (x == 7bits)
0000 0080-0000 07FF 110xxxxx 10xxxxxx (x == 11bits)
0000 0800-0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx (x == 16bits)
0001 0000-001F FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (x == 21bits)
0020 0000-03FF FFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx (x == 26bits)
0400 0000-7FFF FFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx (x == 31bits)
대략 한글/한자를 비롯한 대부분의 문자가 포함된 UCS-2 정도의 범위(16bits)는 3바이트로 모두 표현할 수 있으므로 사실상 거의 모든 문서가 여기에 속할 것입니다. 또한, 현재의 유니코드가 U+10FFFF(21비트의 범위)까지 정의돼 있으므로 현실적으로는 4바이트를 넘는 경우는 없습니다. 따라서 6바이트까지는 향후를 위한 예약 공간 정도로만 보면 될 텐데요, 그런데 위의 인코딩 표를 보면 알겠지만 이론상으로는 최대 8바이트까지 늘어나는 것도 가능합니다.
0400 0000-7FFF FFFF 11111110 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx (x == 36bits) - 7 bytes
0400 0000-7FFF FFFF 11111111 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx (x == 42bits) - 8 bytes
그럼, 이제 대충 SBCS, DBCS, MBCS에 대해 감이 잡히셨겠죠? ^^
참고로,
마이크로소프트의 문서에서 설명하는 DBCS를 보면,
Your applications use DBCS Windows code pages with the "A" versions of Windows functions. See Conventions for Function Prototypes and Code Pages. To help identify a DBCS code page, an application can use the GetCPInfo or GetCPInfoEx function. An application can use the IsDBCSLeadByte function to determine if a given value can be used as the lead byte of a 2-byte character. In addition, an application can use the MultiByteToWideChar and WideCharToMultiByte functions to map between Unicode and DBCS strings.
Win32 API의 A 버전 함수들이 DBCS를 사용한다고 언급하는데요, 엄밀히는 코드 페이지에 따라 달라지기 때문에 확인이 필요합니다.
Code Pages
; https://learn.microsoft.com/en-us/windows/win32/intl/code-pages
이를 위해 사용할 수 있는 함수가 GetCPInfo(Ex)인데,
GetCPInfo function (winnls.h)
; https://learn.microsoft.com/en-us/windows/win32/api/winnls/nf-winnls-getcpinfo
BOOL GetCPInfo([in] UINT CodePage, [out] LPCPINFO lpCPInfo);
CPINFO structure (winnls.h)
; https://learn.microsoft.com/en-us/windows/win32/api/winnls/ns-winnls-cpinfo
typedef struct _cpinfo {
UINT MaxCharSize;
BYTE DefaultChar[MAX_DEFAULTCHAR];
BYTE LeadByte[MAX_LEADBYTES];
} CPINFO, *LPCPINFO;
이와 함께
EnumSystemCodePages 사용을 곁들이면 시스템에서 사용할 수 있는 모든 Character Set의 MaxCharSize를 알아낼 수 있습니다. 아래는 C#으로 구현해 본 예제입니다.
using System;
using System.Runtime.CompilerServices;
using System.Runtime.InteropServices;
namespace ConsoleApp1;
public unsafe struct CPINFO
{
public const int MAX_DEFAULTCHAR = 2;
public const int MAX_LEADBYTES = 12;
public uint MaxCharSize;
public fixed byte DefaultChar[MAX_DEFAULTCHAR];
public fixed byte LeadByte[MAX_LEADBYTES];
}
[StructLayout(LayoutKind.Sequential, Pack = 1, CharSet = CharSet.Unicode)]
public unsafe struct CPINFOEXW
{
public const int MAX_DEFAULTCHAR = 2;
public const int MAX_LEADBYTES = 12;
public const int MAX_PATH = 260;
public uint MaxCharSize;
public fixed byte DefaultChar[MAX_DEFAULTCHAR];
public fixed byte LeadByte[MAX_LEADBYTES];
public char UnicodeDefaultChar;
public uint CodePage;
public fixed char CodePageName[MAX_PATH];
}
internal unsafe class Program
{
public const int CP_INSTALLED = 0x00000001; // installed code page ids
public const int CP_SUPPORTED = 0x00000002; // supported code page ids
[DllImport("kernel32.dll")]
public static extern int GetACP();
[DllImport("kernel32.dll")]
public static extern bool GetCPInfo(uint codePage, out CPINFO lpCPInfo);
[DllImport("kernel32.dll")]
public static extern bool GetCPInfoExW(uint codePage, uint dwFlags, out CPINFOEXW lpCPInfo);
[DllImport("kernel32.dll")]
public static extern bool EnumSystemCodePages(delegate* unmanaged[Stdcall]<nint, int> lpCodePageEnumProc, uint dwFlags);
static void Main(string[] args)
{
delegate* unmanaged[Stdcall]<nint, int> lpCallback = &CodePageEnumProc;
EnumSystemCodePages(lpCallback, CP_INSTALLED);
Console.WriteLine();
Console.WriteLine($"ACP: {GetACP()}");
}
[UnmanagedCallersOnly(CallConvs = new Type[] { typeof(CallConvStdcall) })]
static int CodePageEnumProc(nint codePage)
{
string? text = Marshal.PtrToStringAnsi(codePage);
if (text is null)
{
return 1;
}
uint cpid = uint.Parse(text);
CPINFOEXW cpInfo = new CPINFOEXW();
GetCPInfoExW(cpid, 0, out cpInfo);
switch (cpid)
{
case 1147:
text = $"{cpid,-5} (IBM EBCDIC - France (20297 + Euro)"; // https://learn.microsoft.com/en-us/windows/win32/intl/code-page-identifiers
break;
case 20949:
text = $"{cpid,-5} (Korean Wansung)"; // https://learn.microsoft.com/en-us/windows/win32/intl/code-page-identifiers
break;
}
nint ptr = (nint)cpInfo.CodePageName;
string? codePageName = Marshal.PtrToStringUni(ptr);
if (string.IsNullOrEmpty(codePageName) == false)
{
text = codePageName;
}
Console.Write(text);
switch (cpInfo.MaxCharSize)
{
case 1:
Console.Write(" - SBCS");
break;
case 2:
Console.Write(" - DBCS");
break;
default:
Console.Write($" - might be MBCS (MaxCharSize: {cpInfo.MaxCharSize})");
break;
}
Console.WriteLine();
return 1;
}
}
Windows 11에서 실행해 보면 이런 결과가 나옵니다.
10000 (MAC - Roman) - SBCS
10001 (MAC - Japanese) - DBCS
10002 (MAC - Traditional Chinese Big5) - DBCS
10003 (MAC - Korean) - DBCS
10004 (MAC - Arabic) - SBCS
10005 (MAC - Hebrew) - SBCS
10006 (MAC - Greek I) - SBCS
10007 (MAC - Cyrillic) - SBCS
10008 (MAC - Simplified Chinese GB 2312) - DBCS
10010 (MAC - Romania) - SBCS
10017 (MAC - Ukraine) - SBCS
10021 (MAC - Thai) - SBCS
10029 (MAC - Latin II) - SBCS
10079 (MAC - Icelandic) - SBCS
10081 (MAC - Turkish) - SBCS
10082 (MAC - Croatia) - SBCS
1026 (IBM EBCDIC - Turkish (Latin-5)) - SBCS
1047 (IBM EBCDIC - Latin-1/Open System) - SBCS
1140 (IBM EBCDIC - U.S./Canada (37 + Euro)) - SBCS
1141 (IBM EBCDIC - Germany (20273 + Euro)) - SBCS
1142 (IBM EBCDIC - Denmark/Norway (20277 + Euro)) - SBCS
1143 (IBM EBCDIC - Finland/Sweden (20278 + Euro)) - SBCS
1144 (IBM EBCDIC - Italy (20280 + Euro)) - SBCS
1145 (IBM EBCDIC - Latin America/Spain (20284 + Euro)) - SBCS
1146 (IBM EBCDIC - United Kingdom (20285 + Euro)) - SBCS
1147 (IBM EBCDIC - France (20297 + Euro) - SBCS
1148 (IBM EBCDIC - International (500 + Euro)) - SBCS
1149 (IBM EBCDIC - Icelandic (20871 + Euro)) - SBCS
1250 (ANSI - Central Europe) - SBCS
1251 (ANSI - Cyrillic) - SBCS
1252 (ANSI - Latin I) - SBCS
1253 (ANSI - Greek) - SBCS
1254 (ANSI - Turkish) - SBCS
1255 (ANSI - Hebrew) - SBCS
1256 (ANSI - Arabic) - SBCS
1257 (ANSI - Baltic) - SBCS
1258 (ANSI/OEM - Viet Nam) - SBCS
1361 (Korean - Johab) - DBCS
20000 (CNS - Taiwan) - DBCS
20001 (TCA - Taiwan) - DBCS
20002 (Eten - Taiwan) - DBCS
20003 (IBM5550 - Taiwan) - DBCS
20004 (TeleText - Taiwan) - DBCS
20005 (Wang - Taiwan) - DBCS
20105 (IA5 IRV International Alphabet No.5) - SBCS
20106 (IA5 German) - SBCS
20107 (IA5 Swedish) - SBCS
20108 (IA5 Norwegian) - SBCS
20127 (US-ASCII) - SBCS
20261 (T.61) - DBCS
20269 (ISO 6937 Non-Spacing Accent) - SBCS
20273 (IBM EBCDIC - Germany) - SBCS
20277 (IBM EBCDIC - Denmark/Norway) - SBCS
20278 (IBM EBCDIC - Finland/Sweden) - SBCS
20280 (IBM EBCDIC - Italy) - SBCS
20284 (IBM EBCDIC - Latin America/Spain) - SBCS
20285 (IBM EBCDIC - United Kingdom) - SBCS
20290 (IBM EBCDIC - Japanese Katakana Extended) - SBCS
20297 (IBM EBCDIC - France) - SBCS
20420 (IBM EBCDIC - Arabic) - SBCS
20423 (IBM EBCDIC - Greek) - SBCS
20424 (IBM EBCDIC - Hebrew) - SBCS
20833 (IBM EBCDIC - Korean Extended) - SBCS
20838 (IBM EBCDIC - Thai) - SBCS
20866 (Russian - KOI8) - SBCS
20871 (IBM EBCDIC - Icelandic) - SBCS
20880 (IBM EBCDIC - Cyrillic (Russian)) - SBCS
20905 (IBM EBCDIC - Turkish) - SBCS
20924 (IBM EBCDIC - Latin-1/Open System (1047 + Euro)) - SBCS
20932 (JIS X 0208-1990 & 0212-1990) - DBCS
20936 (Simplified Chinese GB2312) - DBCS
20949 (Korean Wansung) - DBCS
21025 (IBM EBCDIC - Cyrillic (Serbian, Bulgarian)) - SBCS
21027 (Ext Alpha Lowercase) - SBCS
21866 (Ukrainian - KOI8-U) - SBCS
28591 (ISO 8859-1 Latin I) - SBCS
28592 (ISO 8859-2 Central Europe) - SBCS
28593 (ISO 8859-3 Latin 3) - SBCS
28594 (ISO 8859-4 Baltic) - SBCS
28595 (ISO 8859-5 Cyrillic) - SBCS
28596 (ISO 8859-6 Arabic) - SBCS
28597 (ISO 8859-7 Greek) - SBCS
28598 (ISO 8859-8 Hebrew: Visual Ordering) - SBCS
28599 (ISO 8859-9 Latin 5) - SBCS
28603 (ISO 8859-13 Latin 7) - SBCS
28605 (ISO 8859-15 Latin 9) - SBCS
37 (IBM EBCDIC - U.S./Canada) - SBCS
38598 (ISO 8859-8 Hebrew: Logical Ordering) - SBCS
437 (OEM - United States) - SBCS
500 (IBM EBCDIC - International) - SBCS
50220 (ISO-2022 Japanese with no halfwidth Katakana) - might be MBCS (MaxCharSize: 5)
50221 (ISO-2022 Japanese with halfwidth Katakana) - might be MBCS (MaxCharSize: 5)
50222 (ISO-2022 Japanese JIS X 0201-1989) - might be MBCS (MaxCharSize: 5)
50225 (ISO-2022 Korean) - might be MBCS (MaxCharSize: 5)
50227 (ISO-2022 Simplified Chinese) - might be MBCS (MaxCharSize: 5)
50229 (ISO-2022 Traditional Chinese) - might be MBCS (MaxCharSize: 5)
51949 (EUC-Korean) - DBCS
52936 (HZ-GB2312 Simplified Chinese) - might be MBCS (MaxCharSize: 5)
54936 (GB18030 Simplified Chinese) - might be MBCS (MaxCharSize: 4)
55000 (SMS GSM 7bit) - DBCS
55001 (SMS GSM 7bit Spanish) - DBCS
55002 (SMS GSM 7bit Portuguese) - DBCS
55003 (SMS GSM 7bit Turkish) - DBCS
55004 (SMS GSM 7bit Greek) - DBCS
57002 (ISCII - Devanagari) - might be MBCS (MaxCharSize: 4)
57003 (ISCII - Bengali) - might be MBCS (MaxCharSize: 4)
57004 (ISCII - Tamil) - might be MBCS (MaxCharSize: 4)
57005 (ISCII - Telugu) - might be MBCS (MaxCharSize: 4)
57006 (ISCII - Assamese) - might be MBCS (MaxCharSize: 4)
57007 (ISCII - Odia (Oriya)) - might be MBCS (MaxCharSize: 4)
57008 (ISCII - Kannada) - might be MBCS (MaxCharSize: 4)
57009 (ISCII - Malayalam) - might be MBCS (MaxCharSize: 4)
57010 (ISCII - Gujarati) - might be MBCS (MaxCharSize: 4)
57011 (ISCII - Punjabi (Gurmukhi)) - might be MBCS (MaxCharSize: 4)
708 (Arabic - ASMO) - SBCS
720 (Arabic - Transparent ASMO) - SBCS
737 (OEM - Greek 437G) - SBCS
775 (OEM - Baltic) - SBCS
850 (OEM - Multilingual Latin I) - SBCS
852 (OEM - Latin II) - SBCS
855 (OEM - Cyrillic) - SBCS
857 (OEM - Turkish) - SBCS
858 (OEM - Multilingual Latin I + Euro) - SBCS
860 (OEM - Portuguese) - SBCS
861 (OEM - Icelandic) - SBCS
862 (OEM - Hebrew) - SBCS
863 (OEM - Canadian French) - SBCS
864 (OEM - Arabic) - SBCS
865 (OEM - Nordic) - SBCS
866 (OEM - Russian) - SBCS
869 (OEM - Modern Greek) - SBCS
870 (IBM EBCDIC - Multilingual/ROECE (Latin-2)) - SBCS
874 (ANSI/OEM - Thai) - SBCS
875 (IBM EBCDIC - Modern Greek) - SBCS
932 (ANSI/OEM - Japanese Shift-JIS) - DBCS
936 (ANSI/OEM - Simplified Chinese GBK) - DBCS
949 (ANSI/OEM - Korean) - DBCS
950 (ANSI/OEM - Traditional Chinese Big5) - DBCS
65000 (UTF-7) - might be MBCS (MaxCharSize: 5)
65001 (UTF-8) - might be MBCS (MaxCharSize: 4)
결과에서 알 수 있듯이 의외로 SBCS, DBCS 이외에 4바이트, 5바이트까지 사용하는 코드 페이지가 있습니다. 참고로,
코드 페이지 열거는 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage 레지스트리를 참조해도 됩니다.
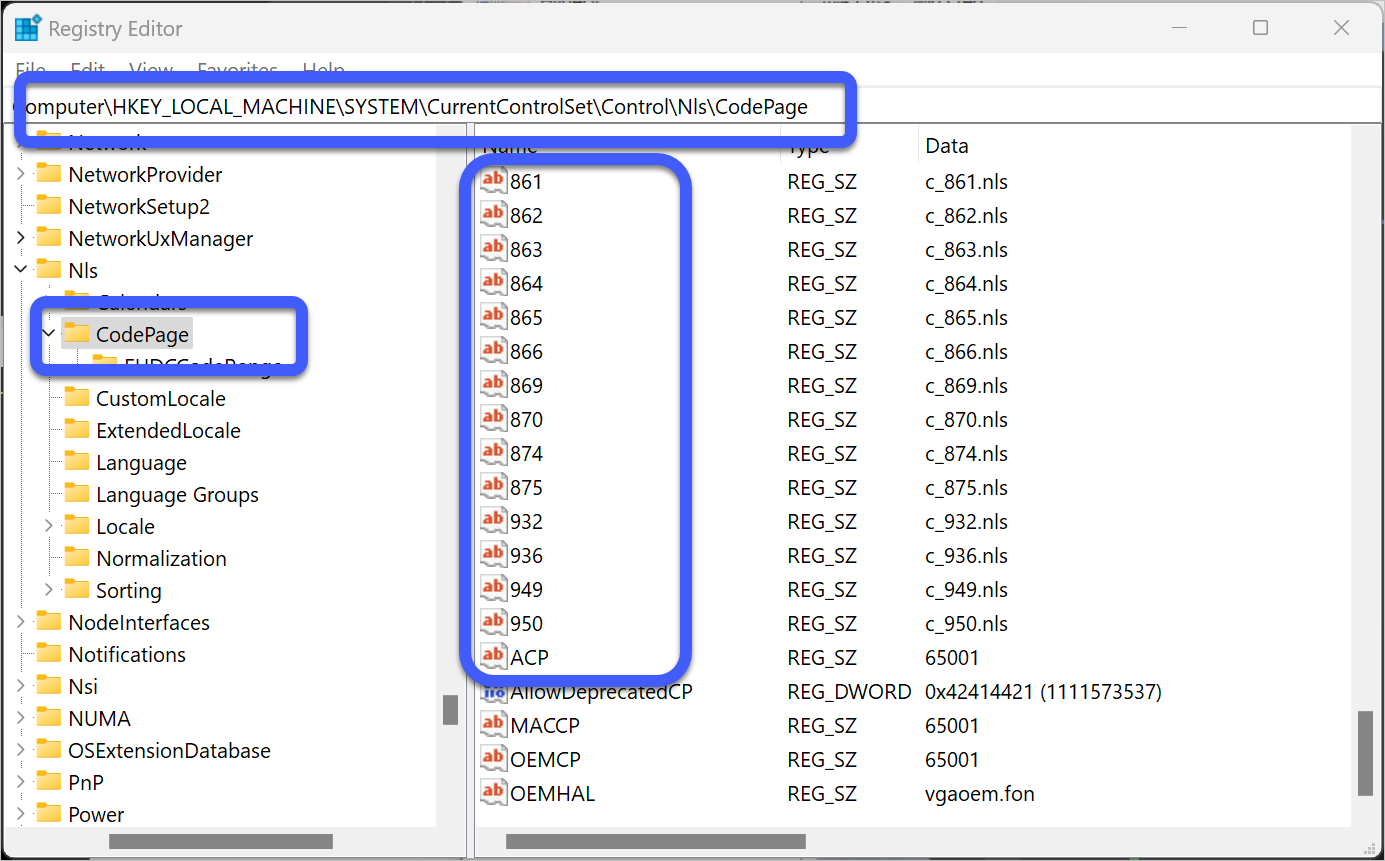
(
첨부 파일은 이 글의 예제 코드를 포함합니다.)
정리해 보면, Win32 API의 A 버전 함수들은 Code page에 따라 SBCS, DBCS, MBCS를 사용하는 것이 결정됩니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]