C/C++ - 소스코드 파일의 인코딩, 바이너리 모듈 상태의 인코딩
개발자가 작성하는 소스코드는 텍스트 파일이고, 그 파일의 인코딩 방식은 개발자가 선택할 수 있습니다. 물론 대부분의 개발자들은 IDE의 기본값을 따를 텐데요, "한글 Windows 11" + "비주얼 스튜디오 2022" 환경이라면 C/C++ 프로젝트를 생성 시 소스코드 파일에 대해 UTF-8(with BOM) 인코딩을 기본으로 설정합니다.
반면 "영문 Windows 11"의 경우에는 "Western European (Windows)" 인코딩을 합니다. 그래서, 해당 소스코드에 한글 문자를 추가하고,
// 영문 Windows 11 + Visual Studio 2022 환경
#include <iostream>
int main()
{
const char* text = "한글";
printf("Koean %s\n", text);
}
저장을 시도하면 이런 메시지를 보게 됩니다.
Some Unicode characters in this file could not be saved in the current codepage. Do you want to resave the file as Unicode in order to maintain your data?
이후 저장하면 UTF-8(with BOM)로 소스코드를 저장합니다. (만약, 이렇게 묻는 창이 귀찮다면
"Save documents as Unicode when data cannot be saved in codepage" 옵션을 켜도 됩니다.)
또는, 원한다면 얼마든지 다른 인코딩 방식으로 저장하는 것이 가능합니다. 이를 위해 "File" / "Save ... As" 메뉴를 선택해 뜨는 "Save As" 대화상자에서, "Save" 버튼의 우측에 있는 화살표를 펼쳐 "Save with Encoding..." 옵션을 선택하면,
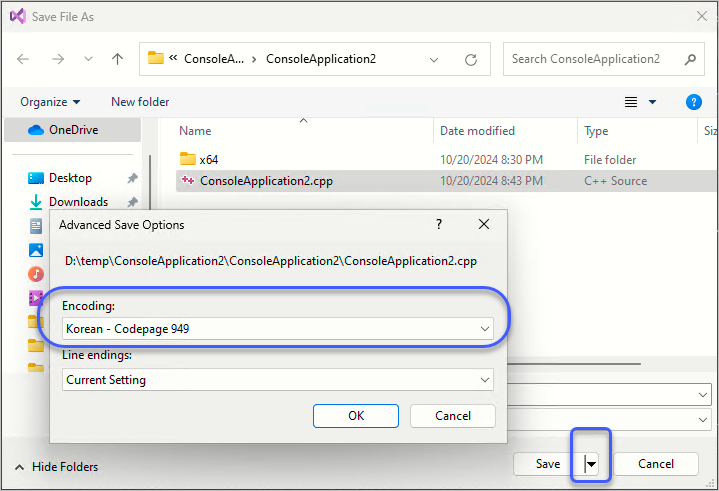
"Encoding" 목록을 통해 시스템이 제공하는 인코딩 방식을 선택할 수 있습니다.
근래에는 대부분 UTF-8로 인코딩을 하겠지만, 굳이 최소한의 기준을 제시한다면 Unicode 관련 인코딩이면 됩니다. 그래야만, 전혀 다른 Locale을 쓰는 동료 개발자의 PC에서도 해당 파일을 정상적으로 읽을 수 있기 때문입니다.
일단, 파일의 인코딩이 제대로 되었다면 그것을 읽어내는 측에서 문제없이 '문자'를 해석해 낼 수 있습니다. 하지만, 그렇다고 해서 "소스코드"가 컴파일된 "바이너리"에 대해서도 동일한 인코딩이 전달되는 것은 아닙니다.
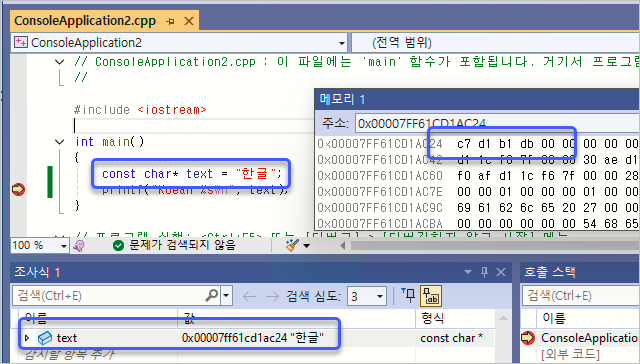
가령, "UTF-8 with BOM"으로 저장한 소스코드에 다음과 같이 한글이 포함된 경우,
// 한글 Windows 11 + Visual Studio 2022 환경
// "UTF-8 with BOM" 저장, Visual C++ 컴파일러로 빌드
#include <iostream>
int main()
{
const char* text = "한글";
printf("Koean %s\n", text); // 이곳에 BP를 걸어 디버깅 시작
}
빌드 및 디버깅을 하면 "text" 변수가 가리키는 메모리에는 "한(0xd1c7) 글(0xdbb1)" 2개의 문자가 "Korean - Codepage 949" 인코딩으로 저장돼 있는 것을 확인할 수 있습니다.
또는 영문 Windows 11에서 UTF-8(BOM)으로 저장한 위의 코드를 빌드하면,
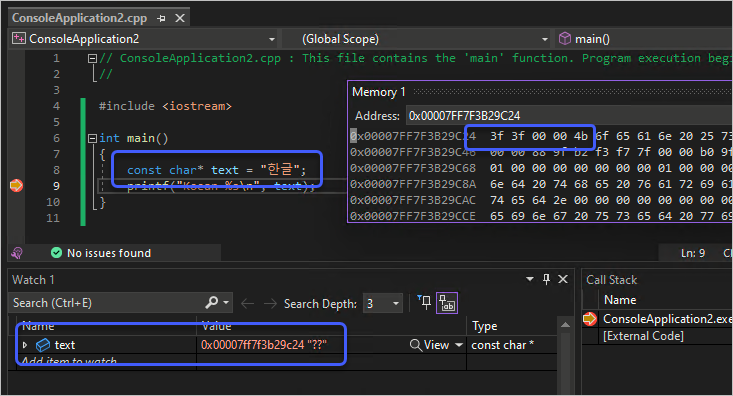
각각의 문자에 대해 "?"로 표현이 됩니다. 왜냐하면, "한글"에 해당하는 문자를 현재 시스템의 인코딩인 "Western European (Windows) - Codepage 1252"로는 표현할 수 없기 때문에 C++ 컴파일러는
fallback 문자인 "?"로 대체해 출력한 것입니다.
위의 내용에 대해 문서에서는 다음과 같이 기록하고 있습니다.
(재미있는 건, 동일한 "영문 Windows 11 + Visual Studio 2022" 상황에서 "UTF-8 without BOM"으로 저장한 소스코드를 빌드하면, text 변수에 "ed 95 9c ea b8 80 00" 값으로 "한글" 문자열이 UTF-8로 저장됩니다.)
결국, 소스코드의 인코딩 방식과 바이너리 상태의 인코딩 방식은 다름을 알아야 합니다. 특히 Visual C++의 경우,
A/W 버전에 대해 char, wchar_t로 나뉘어서 표현을 하는데요, char은 현재 시스템의 인코딩을, wchar_t는 UTF-16 인코딩을 사용하게 됩니다.
Visual C++
char => (입력 파일의 문자만 적절하게 해석한다면) 출력을 시스템의 코드 페이지에 기반한 인코딩으로 변환
wchar_t => (입력 파일의 문자만 적절하게 해석한다면) 출력을 UTF-16으로 변환
실제로 위에서 했던 것과 동일하게 "한글" 문자열을 출력하는 코드를 wchar_t로 변경하면,
// 한글/영문 상관없이 Windows 11 + Visual Studio 2022 환경
// "UTF-8 with BOM" 저장, Visual C++ 컴파일러로 빌드
#include <iostream>
int main()
{
const wchar_t* text = L"한글";
wprintf(L"Koean %s\n", text); // 이곳에 BP를 걸어 디버깅 시작
}
디버깅 시 text 메모리 위치에는 "한(
0xd55c) 글(
0xae00)" 2개의 문자가 UTF-16으로 저장돼 있는 것을 확인할 수 있습니다.
위의 결과에 따라, wchar_t는 유니코드 인코딩을 사용하므로 바이너리에 출력된 데이터 자체에는 문제가 없습니다. 그렇다면 문제는 char인데요, 다행히 char 타입이 utf-8 인코딩에 적합한 타입이어서 이것 역시 유니코드 영역으로 가져올 수 있습니다. 이를 위해 Visual C++에서 제공하는 옵션이 execution_character_set 확장 지시자입니다.
// https://learn.microsoft.com/en-us/cpp/preprocessor/execution-character-set
#pragma execution_character_set("utf-8")
위의 지시자를 이용하면,
// 한글/영문 상관없이 Windows 11 + Visual Studio 2022 환경
// "UTF-8 with BOM" 저장, Visual C++ 컴파일러로 빌드
#include <iostream>
#pragma execution_character_set( "utf-8" )
int main()
{
const char* text = "한글";
printf("Koean %s\n", text); // 이곳에 BP를 걸어 디버깅 시작
}
char 변수(text)에는 utf-8 인코딩이 된 "한(ed 95 9c) 글(ea b8 80)" 데이터가 들어갑니다. 현재 이와 관련한 옵션은 약간의 발전을 거쳤는데요, 그래서 Visual Studio 2015 이후 execution_character_set 지시자는 deprecated로 지정됐고, 아예 컴파일러 옵션으로 /execution-charset이 추가됐습니다.
/execution-charset (Set execution character set)
; https://learn.microsoft.com/en-us/cpp/build/reference/execution-charset-set-execution-character-set
이에 더해, 자주 사용하는 utf-8 인코딩을 위해 전용으로 /utf-8 옵션도 추가되었습니다.
/utf-8 (Set source and execution character sets to UTF-8)
; https://learn.microsoft.com/en-us/cpp/build/reference/utf-8-set-source-and-executable-character-sets-to-utf-8
이러한 컴파일러 옵션뿐만 아니라, 소스코드에서도 (바이너리에 출력될) 인코딩 방식을 지정하는 옵션이 추가되었는데요, 그것이 바로 u8, u, U 리터럴입니다.
String and character literals (C++)
; https://learn.microsoft.com/en-us/cpp/cpp/string-and-character-literals-cpp
no prefix: single-byte or multi-byte
u8: UTF-8
L: wide character (UCS-2 or UTF-16)
u: UTF-16
U: UTF-32
그래서 utf-8 리터럴은 이런 식으로 사용해,
// ISO C++17 표준(/std:c++17) 이하
const char* text = u8"한글"; // utf-8 인코딩: ed 95 9c ea b8 80
// ISO C++20 표준(/std:c++20) 이상
const char8_t* text = u8"한글"; // utf-8 인코딩: ed 95 9c ea b8 80
결국 빌드 결과물에도 utf-8 인코딩이 적용돼 저장이 됩니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]