eBPF의 2가지 방식 - libbcc와 libbpf(CO-RE)
초기에는 eBPF를 libbcc를 이용해 개발을 했는데요, 이 방식의 특징은 eBPF 코드를 "텍스트"로 포함한 뒤, 대상 리눅스 머신에서 실행하는 시점에 컴파일을 하고 로드하는 방식이라는 점입니다.
Why libbpf and BPF CO-RE?
; https://nakryiko.com/posts/bcc-to-libbpf-howto-guide/#why-libbpf-and-bpf-co-re
Historically, BCC was a framework of choice when you had to develop a BPF application that required peering into the internals of the kernel when implementing all sorts of tracing BPF programs. BCC provided a built-in Clang compiler that could compile your BPF code in runtime, tailoring it to a specific target kernel on the host. This was the only way to develop a maintainable BPF application that had to deal with internals of an ever-changing kernel.
웹상에 eBPF 코드 예제를 찾아보면, 대표적으로 파이썬 코드들이 그런 방식에 속하는데요,
#!/usr/bin/python3
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname ("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print()
위의 프로그램을 실행하면, 파이썬 런타임이 대상 컴퓨터에서 실행되는 시점에 eBPF 코드를 clang/libbcc를 이용해 컴파일하고 로드합니다. 그러니까, 커널 의존적인 접근을 실행 시점에 컴파일함으로써 해결하고 있는 것입니다.
반면 libbpf를 이용한 방법은,
libbpf/libbpf
; https://github.com/libbpf/libbpf#bpf-co-re-compile-once--run-everywhere
// BPF loader (libbpf)
//
https://nakryiko.com/posts/bpf-portability-and-co-re/#bpf-loader-libbpf
All the previous pieces of data (kernel BTF and Clang relocations) are coming together and are processed by libbpf, which serves as a BPF program loader. It takes compiled BPF ELF object file, post-processes it as necessary, sets up various kernel objects (maps, programs, etc), and triggers BPF program loading and verification.
eBPF 코드를 "바이트 코드"로 한 번 컴파일하는 작업을 수행한 뒤, 실행 시에는 (clang/libbcc 의존 없이) 대상 환경에서 바로 로드하면서 약간의 post-process 작업을 하는 식입니다.
따라서, CO-RE(Compile Once - Run Everywhere)라는 말은 eBPF 프로그램 중에서도 기존의 libbcc 방식이 아닌, 새롭게 나온 libbpf에서만 가능한 유형입니다.
아래의 글에 이에 대한 방식의 차이점을 잘 설명하고 있는데요,
Hello eBPF: First steps with libbpf (5)
; https://mostlynerdless.de/blog/2024/02/26/hello-ebpf-first-steps-with-libbpf-5/
위에서는 Python이 아닌 Java를 이용한 BPF 예제를 소개하고 있는데, libbcc와 libbpf를 이용할 때의 차이점을 아래 그림으로 잘 표현하고 있습니다.
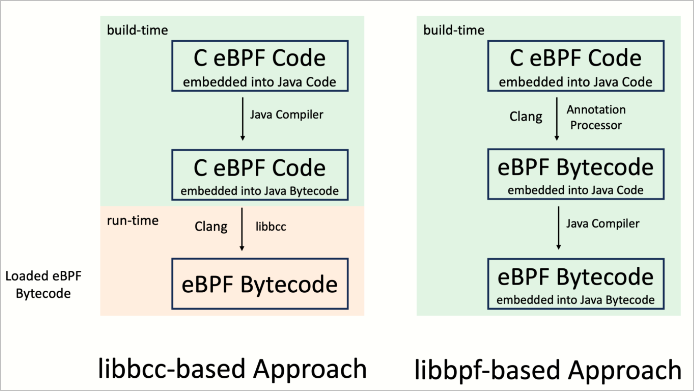
그렇다면, 제가
이전에 소개한 bpf2go를 이용한 프로그램은 어떤 방식일까요? 예상하시겠지만 bpf2go를 이용해 미리 eBPF 코드를 컴파일한 다음, 런타임 시에 "로드"만 한 후 실행하기 때문에 libbpf를 이용한 방식에 속합니다.
사실, 어느 한 쪽의 방식이 절대적인 장점을 갖고 있진 않습니다. libbcc는 파이썬과 같은 인터프리터 언어에서도 쉽게 사용할 수 있지만 clang/libbcc에 대한 의존을 가지고 있어 3rd-party 라이브러리나 독립적인 응용 프로그램을 제작/배포하는 시나리오에서는 약간 불편한 점이 있습니다. 만약 "그 정도의 의존성"이라고 생각한다면 libbcc를 이용한 방식도 괜찮지만, "의존성이 없는" 방식을 선호한다면 libbpf를 이용한 방식을 선택하는 것이 좋습니다.
따라서, python으로 개발한 방식은 시스템에 bpfcc-tools 패키지를 반드시 설치해야 하지만, bpf2go를 이용한 방식은 아무런 의존성 없이 그 프로그램을 곧바로 실행할 수 있습니다.
대충 어떤 차이점이 있는지 아시겠죠? ^^
기존 libbcc에서 libbpf 방식으로의 변경은 eBPF 코드에서도 수정이 필요하다고 합니다.
BPF code conversion
; https://nakryiko.com/posts/bcc-to-libbpf-howto-guide/#bpf-code-conversion
위의 글에 나온 내용을 간략히 정리해 볼까요? ^^
1. Detecting BCC vs libbpf modes
먼저 기존 환경에 대한 호환성을 확보해야 한다면, eBPF 소스코드를 libbcc, libbpf 2개에 맞춰 관리를 해야 할 텐데요, 다행히 기존 BCC 헤더에는 이렇게 매크로가 정의돼 있으므로,
#ifdef BCC_SEC
#define __BCC__
#endif
우리가 만드는 코드에서 바로 그 매크로 정의(__BCC__)를 이용해 코드 선택을 할 수 있다고 합니다.
#ifdef __BCC__
/* BCC-specific code */
#else
/* libbpf-specific code */
#endif
2. Header includes
libbpf/BPF CO-RE를 위해서는 리눅스 커널 헤더를 직접 include하는 방식에서, vmlinux.h를 포함하는 것으로 바꿔야 한다고 합니다.
eBPF - vmlinux.h 헤더 포함하는 방법 (bpf2go에서 사용)
; https://www.sysnet.pe.kr/2/0/13783
따라서 __BCC__를 이용한다면 대충 이렇게 처리할 수 있습니다.
#ifdef __BCC__
/* linux headers needed for BCC only */
#else /* __BCC__ */
#include "vmlinux.h" /* all kernel types */
#include <bpf/bpf_helpers.h> /* most used helpers: SEC, __always_inline, etc */
#include <bpf/bpf_core_read.h> /* for BPF CO-RE helpers */
#include <bpf/bpf_tracing.h> /* for getting kprobe arguments */
#endif /* __BCC__ */
3. Field accesses
기존 libbcc 방식은 소스코드에 사용한 커널 구조체의 필드 접근에 대해,
{
struct task_struct* task = (struct task_struct*)bpf_get_current_task();
pid_t pid = task->parent->pid;
bpf_printk("parent-pid == %x\n", pid);
return 0;
}
라이브러리 자체적으로 bpf_probe_read로 미리 번역하는 작업을 할 수 있었다고 합니다. 하지만 libbpf 방식에서는 저런 단계를 거칠 수 없으므로 빌드 시 이런 오류가 발생합니다.
field KprobeSysClone: program kprobe_sys_clone: load program: permission denied: 1: (79) r1 = *(u64 *)(r0 +2520): R0 invalid mem access 'scalar' (5 line(s) omitted)
따라서 개발자가 직접 bpf_probe_read를 호출해 필드를 접근하는 것으로, 또는 그 과정을 편리하게 해주는 BPF_CORE_READ를 이용해야 합니다.
SEC("kprobe/sys_clone") int BPF_KPROBE(kprobe_sys_clone, unsigned long clone_flags)
{
struct task_struct* task = (struct task_struct*)bpf_get_current_task();
pid_t pid = BPF_CORE_READ(task, parent, pid);
bpf_printk("parent-pid == %d\n", pid);
return 0;
}
#define __CORE_RELO(src, field, info) \
__builtin_preserve_field_info((src)->field, BPF_FIELD_##info)
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
#define __CORE_BITFIELD_PROBE_READ(dst, src, fld) \
bpf_probe_read_kernel( \
(void *)dst, \
__CORE_RELO(src, fld, BYTE_SIZE), \
(const void *)src + __CORE_RELO(src, fld, BYTE_OFFSET))
#else
/* semantics of LSHIFT_64 assumes loading values into low-ordered bytes, so
* for big-endian we need to adjust destination pointer accordingly, based on
* field byte size
*/
#define __CORE_BITFIELD_PROBE_READ(dst, src, fld) \
bpf_probe_read_kernel( \
(void *)dst + (8 - __CORE_RELO(src, fld, BYTE_SIZE)), \
__CORE_RELO(src, fld, BYTE_SIZE), \
(const void *)src + __CORE_RELO(src, fld, BYTE_OFFSET))
#endif
/*
* Extract bitfield, identified by s->field, and return its value as u64.
* All this is done in relocatable manner, so bitfield changes such as
* signedness, bit size, offset changes, this will be handled automatically.
* This version of macro is using bpf_probe_read_kernel() to read underlying
* integer storage. Macro functions as an expression and its return type is
* bpf_probe_read_kernel()'s return value: 0, on success, <0 on error.
*/
#define BPF_CORE_READ_BITFIELD_PROBED(s, field) ({ \
unsigned long long val = 0; \
\
__CORE_BITFIELD_PROBE_READ(&val, s, field); \
val <<= __CORE_RELO(s, field, LSHIFT_U64); \
if (__CORE_RELO(s, field, SIGNED)) \
val = ((long long)val) >> __CORE_RELO(s, field, RSHIFT_U64); \
else \
val = val >> __CORE_RELO(s, field, RSHIFT_U64); \
val; \
})
4. BPF maps
libbpf에서는 BPF maps를 다루는 방식이 libbcc와 다르다고 합니다. 그런데, 이전과는 다르게 이번에는 오히려 매크로를 안 쓰는 방향으로 바뀌었군요. ^^
/* Array */
#ifdef __BCC__
BPF_ARRAY(my_array_map, struct my_value, 128);
#else
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 128);
__type(key, u32);
__type(value, struct my_value);
} my_array_map SEC(".maps");
#endif
/* Hashmap */
#ifdef __BCC__
BPF_HASH(my_hash_map, u32, struct my_value);
#else
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, struct my_value);
} my_hash_map SEC(".maps")
#endif
/* Per-CPU array */
#ifdef __BCC__
BPF_PERCPU_ARRAY(heap, struct my_value, 1);
#else
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
__uint(max_entries, 1);
__type(key, u32);
__type(value, struct my_value);
} heap SEC(".maps");
#endif
맵의 기본 크기도 바뀌었다고 하는데요, 기존 BCC에서는 10240이었던 것이, libbpf에서는 크기를 명시적으로 설정할 수 있다고 합니다.
그 외에, PERF_EVENT_ARRAY, STACK_TRACE와 몇몇 맵 구현체(DEVMAP, CPUMAP, ...)들은 키/값으로 BTF 타입을 (아직) 사용할 수 없다고 합니다. 따라서, 그 크기를 직접 지정해야 한다고.
/* Perf event array (for use with perf_buffer API) */
#ifdef __BCC__
BPF_PERF_OUTPUT(events);
#else
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} events SEC(".maps");
#endif
5. Accessing BPF maps from BPF code
BCC 방식에서는 map 접근 코드를 마치 C++ 문법처럼 사용할 수 있게 해주고 이후 중간에서 적절한 eBPF 코드로 바꿔주었다고 하는데, 이것 역시 libbpf에서는 개발자가 직접 처리해야 한다고 합니다.
#ifdef __BCC__
struct event *data = heap.lookup(&zero);
#else
struct event *data = bpf_map_lookup_elem(&heap, &zero);
#endif
#ifdef __BCC__
my_hash_map.update(&id, my_val);
#else
bpf_map_update_elem(&my_hash_map, &id, &my_val, 0 /* flags */);
#endif
#ifdef __BCC__
events.perf_submit(args, data, data_len);
#else
bpf_perf_event_output(args, &events, BPF_F_CURRENT_CPU, data, data_len);
#endif
6. BPF programs
eBPF 코드의 함수에는 반드시 SEC() 매크로를 이용한 사용자 정의 섹션명을 지정해야 한다고 합니다.
#if !defined(__BCC__)
SEC("tracepoint/sched/sched_process_exec")
#endif
int tracepoint__sched__sched_process_exec(
#ifdef __BCC__
struct tracepoint__sched__sched_process_exec *args
#else
struct trace_event_raw_sched_process_exec *args
#endif
) {
/* ... */
}
임의로 정할 수 있는 섹션명이긴 하지만 그건 어디까지나 libbpf 개발자들의 입장이고, 그 기반으로 eBPF 프로그램을 작성하는 개발자 입장에서는 libbpf가 정한 이름 규칙을 따라야 합니다.
예를 들면, 이런 식입니다.
- tp/<category>/<name> for tracepoints;
- kprobe/<func_name> for kprobe and kretprobe/<func_name> for kretprobe;
- raw_tp/<name> for raw tracepoint;
- cgroup_skb/ingress, cgroup_skb/egress, and a whole family of cgroup/<subtype> programs.
7. Tracepoints
tracepoint 유형으로 작성된 eBPF 함수의 인자 타입이 BCC 방식에서는 "tracepoint__<category>__<name>" 패턴이었다고 하는데, libbpf에서는 "trace_event_raw_<name>" 형식으로 바뀌었다고 합니다.
그런데, "name" 영역이 좀 애매한 것 같습니다. 가령, "tracepoint/syscalls/sys_enter_connect" 유형인 경우 그것의 이름에서 가장 의미 있는 것은 "connect"와 "enter"일 듯한데요, 실제로 찾아보면,
$ cat vmlinux.h | grep "struct trace_event_raw_sys*"
struct trace_event_raw_sys_enter {
struct trace_event_raw_sys_exit {
"connect"의 의미가 날아간 trace_event_raw_sys_enter가 나옵니다. 다시 말하면, syscalls 유형의 경우 공통적으로 sys_enter, sys_exit 구조체가 매개변수 타입으로 사용된다고 보면 됩니다.
SEC("tracepoint/syscalls/sys_enter_connect")
int sys_enter_connect(struct trace_event_raw_sys_enter *ctx) {
// ...[생략]...
}
// SEC("tp/syscalls/sys_exit_connect")
SEC("tracepoint/syscalls/sys_exit_connect")
int sys_exit_connect(struct trace_event_raw_sys_exit* ctx) {
// ...[생략]...
}
그런데, 때로는 공통 타입을 재사용하기 때문에 "trace_event_raw_<name>" 형식으로 찾을 수 없는 경우도 있다고 합니다. 그 사례로, sched_process_exit가 있습니다.
$ sudo bpftrace -l "tracepoint:*sched_process_exit"
tracepoint:sched:sched_process_exit
일반적인 패턴을 따랐다면 이것의 매개변수 타입은 trace_event_raw_sched_process_exit가 되었어야 하지만, 커널 측에서는 이미 내부에 만들어져 사용하고 있던 타입, 즉 trace_event_raw_sched_process_template을 매개변수 타입으로 사용해야 한다는데... 이건 커널 측 소스코드를 참고하지 않고서는 알아내기가 꽤나 어렵지 않을까 싶습니다.
8. Kprobes
BPF_KPROBE 매크로를 이용해 kprobe를 정의할 때 매개변수를 pt_regs 구조체를 숨긴 채로 열거할 수 있습니다.
#ifdef __BCC__
int kprobe__acct_collect(struct pt_regs *ctx, long exit_code, int group_dead)
#else
SEC("kprobe/acct_collect")
int BPF_KPROBE(kprobe__acct_collect, long exit_code, int group_dead)
#endif
{
/* BPF code accessing exit_code and group_dead here */
}
참고로, syscall 관련 함수의 이름 규칙이 4.17 커널부터 변경되었다고 하는데요,
// https://github.com/torvalds/linux/blob/master/arch/x86/entry/syscall_64.c
#define __SYSCALL(nr, sym) extern long __x64_##sym(const struct pt_regs *);
#define __SYSCALL_NORETURN(nr, sym) extern long __noreturn __x64_##sym(const struct
// https://github.com/torvalds/linux/blob/master/arch/x86/entry/syscall_32.c
#define __SYSCALL(nr, sym) extern long __ia32_##sym(const struct pt_regs *);
#define __SYSCALL_NORETURN(nr, sym) extern long __noreturn __ia32_##sym(const struct pt_regs *);
그전에는 단순히 "sys_kill" 이름이었던 것이, 이제는 플랫폼에 따른 __x64_, __ia32_ 접두사가 붙는다고 합니다.
// https://github.com/torvalds/linux/blob/master/include/uapi/asm-generic/unistd.h#L360
#define __NR_kill 129
__SYSCALL(__NR_kill, sys_kill)
그러고 보니 전에 kprobe를 bpftrace로 테스트할 때는 sys_clone이라고 하면 안 되고, 반드시 __x64_sys_clone으로 지정해야만 했었는데요, 재미있는 건 이것도 프레임워크마다 달라질 수 있으므로 유의해야 합니다. 즉, bpf2go를 사용한 경우에는 그냥 SEC("kprobe/sys_clone")라고 지정해도 잘 동작합니다.
어쨌든, 이런 플랫폼 의존적인 이름 규칙이 싫다면 tracepoint를 사용하는 것이 좋겠습니다.
의미 있는 또 하나의 변화라면, 커널 5.5부터는 tracepoint/kprobe/kretprobe 각각에 대해 그보다 더 성능이 나은 raw_tp/fentry/fexit을 제공한다는 점!
9. Dealing with compile-time #if's in BCC
BCC 방식의 경우, 런타임 시에 컴파일을 하기 때문에 그 시점에 사용자 정의 매크로 변수를 전달하는 것이 가능한 구조였습니다. 하지만, libbpf의 경우에는 미리 컴파일을 하기 때문에 그 과정이 불가능한데요, 대신 이런 간극을 보완할 수 있도록 커널 버전에 따른 분기를 할 수 있는 방법을 제공한다고 합니다.
#define KERNEL_VERSION(a, b, c) (((a) << 16) + ((b) << 8) + (c))
extern int LINUX_KERNEL_VERSION __kconfig;
if (LINUX_KERNEL_VERSION < KERNEL_VERSION(5, 2, 0)) {
/* deal with older kernels */
} else {
/* 5.2 or newer */
}
이와 함께, 현재 커널 빌드 환경에 대한 Kconfig 변수를, 즉 CONFIG_xxx에 해당하는 값을,
// Ubuntu 22.04 환경
$ cat /boot/config-$(uname -r) | grep ^CONFIG_HZ=
CONFIG_HZ=1000
$ cat /boot/config-$(uname -r) | grep ^CONFIG_NLS_DEFAULT
CONFIG_NLS_DEFAULT="utf8"
// WSL + Ubuntu 20.04 환경
$ zcat /proc/config.gz | grep ^CONFIG_HZ=
CONFIG_HZ=100
이렇게 매핑해서 사용할 수 있습니다.
extern int LINUX_KERNEL_VERSION __kconfig;
extern int CONFIG_HZ __kconfig;
extern char CONFIG_NLS_DEFAULT[128] __kconfig;
SEC("tracepoint/syscalls/sys_enter_connect")
int sys_enter_connect(struct trace_event_raw_sys_enter *ctx) {
long unsigned int hz = CONFIG_HZ;
bool is_5_2_or_newer = LINUX_KERNEL_VERSION >= KERNEL_VERSION(5, 2, 0);
if (is_5_2_or_newer)
{
bpf_printk("[new] hz == %d, kernel == %x, nls == %s\n", hz, LINUX_KERNEL_VERSION, CONFIG_NLS_DEFAULT);
}
else
{
bpf_printk("[old] hz == %d, kernel == %x, nls == %s\n", hz, LINUX_KERNEL_VERSION, CONFIG_NLS_DEFAULT);
}
return 0;
}
이 외에도 대상 커널에서 필드의 이름이 변경되었거나 하위 구조체로 위치가 변경된 경우를 감지하기 위해
bpf_core_field_exists 함수가 제공된다고 하는데요, 테스트를 위해 WSL 2 (5.15.153.1-microsoft-standard-WSL2+) 환경의 vmlinux.h에 있는 task_struct 타입에 "unsigned int cpu" 필드를 골라봤습니다.
SEC("tracepoint/syscalls/sys_exit_connect")
int sys_exit_connect(struct trace_event_raw_sys_exit* ctx) {
struct task_struct* task = (struct task_struct *)bpf_get_current_task();
unsigned int cpu_value = 0;
if (bpf_core_field_exists(task->cpu)) {
cpu_value = BPF_CORE_READ(task, cpu);
} else {
cpu_value = -1;
}
bpf_printk("sys_exit_connect - cpu_value == %d\n", cpu_value);
return 0;
}
빌드 후 실행하면 cpu_value가 양수로 나왔는데요, (task_struct.cpu가 존재하지 않는) 6.11.5 버전의 커널 환경에서 실행했더니 eBPF 코드가 실행되면서 cpu_value == -1이 나왔습니다. 참고로, 저 코드의 평가는 실행 시점이 아닌 BPF verifier가 eBPF 코드를 로딩하는 단계에서 이뤄진다는 것입니다. 따라서 verifier는 cpu 필드가 없는 경우 그 브랜치를 "dead code"로 평가하게 되고 아예 삭제를 해버립니다. 따라서, 개발자는 부담 없이 bpf_core_field_exists를 이용한 if 평가를 남용해도 됩니다.
이런 식으로
bpf_core_type_exists,
bpf_core_enum_value_exists가 제공되니 참고하세요.
10. Application configuration
Map 없이도 eBPF 소스코드에 전역 변수를 정의하는 방법이
제공되는데요, 즉 외부에서 자유롭게 설정값을 전달할 수 있어 런타임 시에 동작을 변경할 수 있는 유연함을 제공합니다.
"10. Application configuration" 글의 예제를 보면, process id를 외부에서 설정함으로써 원하는 프로세스와 관련된 정보만을 다루고 있습니다.
bpf2go의 경우 웬일인지 "
Global Variables" 문서에 나오는 대로 현재 실습이 안 됩니다. (loadVariables 함수도 없고, Variables 속성도 없습니다.) 찾아보니까,
New API in Collection{Spec} for modifying global BPF variables #1542
; https://github.com/cilium/ebpf/issues/1542
Collection: add Variables field to interact with global variables #1572
; https://github.com/cilium/ebpf/pull/1572
현재 자동 생성되는 코드에 전역 변수의 get/set 접근자를 추가하는 중인 듯한데요, 아마도 저게 나오면 실습이 되지 않을까 싶습니다.
시간이 되시면 아래의 글도 읽어보세요. ^^
[eBPF] BPF 실행파일 로딩 과정 분석 (JIT)
; https://velog.io/@haruband/eBPF-BPF-실행파일-로딩-과정-분석-JIT
BPF Architecture - JIT
; https://docs.cilium.io/en/stable/bpf/architecture/#jit
eBPF를 실행하시는 시점에서조차도, 그 바이트 코드를 interpreter 형식으로 실행할지, 아니면 JIT를 거쳐 아예 기계어 코드로 변환해 실행할지에 대한 선택도 가능합니다.
[이 글에 대해서 여러분들과 의견을 공유하고 싶습니다. 틀리거나 미흡한 부분 또는 의문 사항이 있으시면 언제든 댓글 남겨주십시오.]